Article
Overcoming LLM Hallucinations with Trustworthiness Scores
Last Updated on October 7, 2025
by White Widget AI and Data Science Team

White Widget Team
Looking to make your AI trustworthy for crucial tasks?
Hallucinations in Large Language Models
Hallucinations in LLMs refer to cases where the model generates information that is incorrect, fabricated, or not supported by the input data.
The Problem with LLM Hallucination
We tackle the tremendous challenge when incorporating Large Language Models into our applications: the models’ tendency to hallucinate information. This is the biggest barrier to trusting and adopting AI across various domains and business, and we have a growing list of cautionary tales where LLM hallucinating led to undesirable consequences.

Fig. 1: Chatbot assured a passenger air travel discounts that are non-existent, and the airline in its defense argued that the chatbot is responsible for its actions. Source: BBC Travel
In 2022, a passenger was misled by the chatbot about applying a bereavement fare for a flight. When the passenger asked for the discount, the airline denied it claiming that the chatbot gave an incorrect information and it was responsible for its actions. The tribunal rejected this defense and the airline was ordered to pay the passenger in damages and fees. This emphasizes that businesses cannot evade liability by blaming AI. The users are also advised to be cautious with information coming from AI chatbots and seek human assistance for accuracy.
With the current standard APIs, it is hard to automatically tell when an LLM may hallucinate responses, which can be dangerous especially when phrased with certainty.
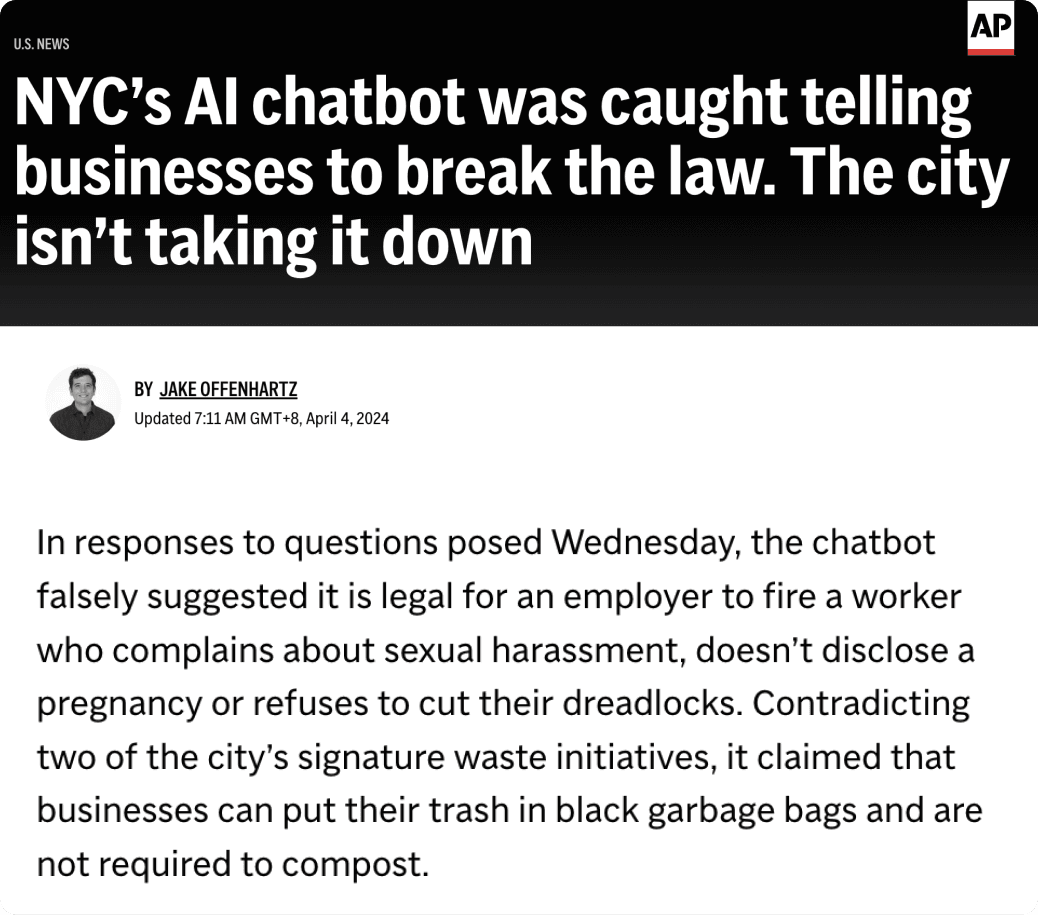
Fig 2: Chatbot was caught giving incorrect, sometimes illegal advice to businesses. Source: AP News
In April 2024, the AI chatbot deployed by the New York City to assist small business owners, has come under the fire for providing incorrect and illegal advice. Despite the surfaced issues by the Markup, the City mayor defended to keep the chatbot online, acknowledging the chatbot’s errors and emphasizing the iterative nature of its development. The chatbot’s behavior underscores the risks of deploying untested AI in public services. The experts have emphasized that public sector chatbots require higher standards of accuracy due to the trust placed in government-provided information. Learning from this incident, some cities like Los Angeles have confined their chatbots to more controlled inputs and prompts to minimize misinformation.
Overcoming Hallucinations
LLMs will always have some form of hallucinations, and with this in mind, how can we minimize the risk coming from inaccurate and hallucinated responses? The number of approaches on detecting LLM hallucination is growing, and in this article we wanted to focus on different dimensions of trustworthiness: Confidence and Consistency.
Confidence
In 2022, OpenAI has published a paper demonstrating the ability of GPT-3 model to express uncertainty about its answers in natural language — without the use of logit probabilities. When given a question, the model generates both an answer and a level of confidence.

Fig. 3: Illustration of GPT-3’s verbalized probability on CalibratedMath tasks, where the LLM is asked with simple math questions. Source: arXiv
The paper has shown that this capability of LLM generalizes well. The study compares the calibration of uncertainty expressed in words (“verbalized probability”) to uncertainty extracted from model logits. Both types of uncertainty demonstrate the ability to generalize calibration under distribution shift. Additionally, evidence is provided that GPT-3’s ability to generalize calibration relies on pre-trained latent representations that correlate with epistemic uncertainty over its answers.
Consistency
The idea is to evaluate whether the model provides consistent answers to a single prompt. If the models are consistent, it is likely to be hallucinating. However, if the responses contradict each other, this may indicate a hallucination. To check consistency, we can ask the model the same question multiple times and compare the responses: if the answers align well and do not contradict each other, it suggests that the model is drawing from a coherent source of the topic. Conversely, if the answers are shown to be inconsistent or contradictory, the inconsistency can indicate potential hallucination. Suppose we ask the LLM the following questions in a single prompt:
Prompt: Who wrote the play ‘Hamlet’?
Response 1: "William Shakespeare wrote the play 'Hamlet'."
Response 2: "The play 'Hamlet' was written by William Shakespeare."
Response 3: "William Shakespeare is the author of 'Hamlet'."
Now, if the responses were:
Response 1: "William Shakespeare wrote the play 'Hamlet'."
Response 2: "Christopher Marlowe wrote 'Hamlet'."
Response 3: "The play 'Hamlet' was written by William Shakespeare."
The inconsistency in Response 2 (incorrectly attributing the play to Christopher Marlowe) suggests a potential hallucination.
Cleanlab’s Trustworthy Language Models
Cleanlab’s Trustworthy Language Models is an extension to our standard large language models that provides trustworthiness score, quantifying the certainty of the model to its answers. The approach combines checking the consistency and the level of confidence of the model’s responses.
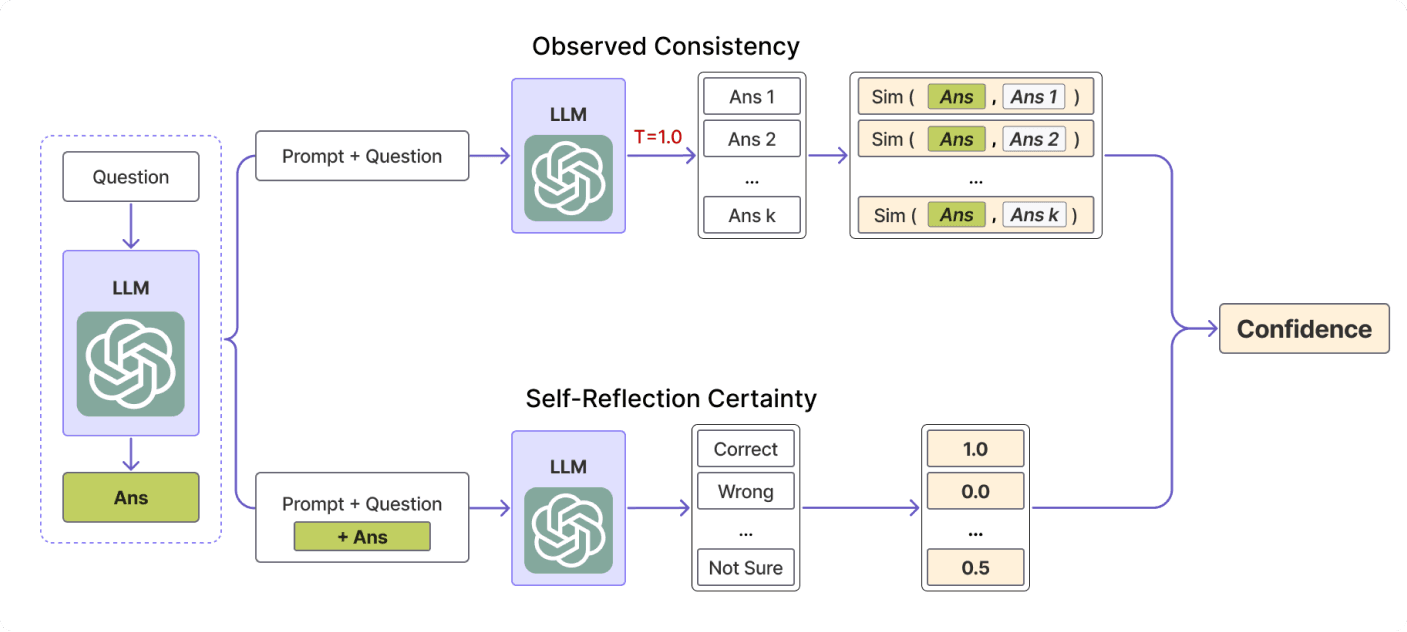
Fig. 4: The pipeline for scoring response based on self-reflection certainty of the model and observed consistency on answers. Source: arXiv
Overall Confidence Estimate O corresponds to observed consistency, S corresponds to Self-Reflection, and Beta is the tradeoff parameter In the paper, it is fixed to 0.7, and if the value is lower the more we trust the LLM’s ability to do calibrated self-reflection assessment of arbitrary(question, answer) pairs.
What is the TLM Score?
The TLM score quantifies our confidence that a response is good for a given prompt. In the context of question-answering applications, a good response means a correct answer. For more open-ended applications, a good response is the one that is helpful, informative and clearly superior to alternative hypothetical responses. We note that the trustworthiness score are particularly useful for requests seeking correct answers rather than for extremely open-ended inquiries. Their trustworthiness score captures two aspects of uncertainty, which are combined into a comprehensive measure:
- Aleatoric Uncertainty: The known unknowns, or the uncertainty the model is aware of due to inherent difficulty of the request e.g., if a prompt is incomplete or vague.
- Epistemic Uncertainty: The unknown unknowns, or the uncertainty stemming from the model’s lack of prior training on required data to give a correct response.
TLM employs several mathematical operations to quantify these uncertainties:
- Self-Reflection (S): The LLM is prompted to explicitly rate its response and state how confidently it perceives the response to be good. This introspective process helps in evaluating the reliability of the answer.
- Observed Consistency (O): The LLM generates multiple plausible responses it believes could be good and measures the degree of contradiction among these responses. Consistency across these responses indicates higher trustworthiness.
- Probabilistic Prediction (P): a process in which we consider the per-token probabilities assigned by a LLM as it generates a response based on the request (auto-regressively token by token).
Incorporating Trustworthiness Scores
Use Case: Langchain’s Extraction Chain and Data Labeling
Suppose that we already have an existing Extraction Service implemented in Langchain:
import pandas as pd
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableLambda, RunnableParallel
class Product(BaseModel):
"""Information about a product."""
name: Optional[str] = Field(default=None, description="The name of the product")
brand: Optional[str] = Field(default=None, description="The brand of the product")
model: Optional[str] = Field(default=None, description="The model of the product")
specs: Optional[str] = Field(default=None, description="Specifications of the product")
price: Optional[str] = Field(default=None, description="Price of the product")
# Custom prompt to provide instructions and additional context
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked to extract, "
"return null for the attribute's value.",
),
("human", "{text}"),
]
)
# Initialize the model that supports function/tool calling
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# Define the runnable with structured output
runnable = prompt | model.with_structured_output(schema=Product)The runnable chain extracts the name, brand, model and specs of a product from a given textual description. For example:
description = "Enjoy powerful sound with the ZEBRONICS Zeb-Astra 20 Wireless BT v5.0 Portable Speaker. 10W RMS Output, TWS, 10H Battery Life. Priced at ₹2,299."
runnable.invoke({"text": description})
# output: Product(name='ZEBRONICS Zeb-Astra 20 Wireless BT v5.0 Portable Speaker', brand=None, model=None, specs='10W RMS Output, TWS, 10H Battery Life', price='₹2,299')Suppose we want to grade the extraction process made at each product descriptions and pass those moderately graded outputs to humans for validation. We can design a Langchain Runnable that scores a given prompt and structured response.
from cleanlab_studio import Studio
import asyncio
CLEAN_LAB_API_KEY = "<Cleanlab's API KEY>"
# Function to initialize CleanLab with API key
def initialize_cleanlab(api_key):
studio = Studio(api_key)
return studio.TLM()
# Function to get trustworthiness score
def get_trustworthiness_score(input_data):
api_key = CLEAN_LAB_API_KEY # Replace with your actual API key
tlm = initialize_cleanlab(api_key)
prompt, response = input_data['prompt'], input_data['response']
trustworthiness_score = tlm.get_trustworthiness_score(prompt, response.__repr__())
return {'response': response, 'trustworthiness_score': trustworthiness_score}
# Function to format prompt to string
def format_prompt_to_string(input_data):
return prompt.format_prompt(**input_data).to_string()
# Function to extract prompt and response
def extract_prompt_and_response(input_data):
return {'prompt': input_data['prompt_string_chain'], 'response': input_data['extraction_chain']}
# Define the CleanLab runnable lambdas
cleanlab_runnable = RunnableLambda(get_trustworthiness_score, name="GetTrustWorthinessScore")
async_cleanlab_runnable = RunnableLambda(async_get_trustworthiness_score, name="AGetTrustWorthinessScore")
# Define the Runnable for converting prompt to string
prompt_to_string_chain = RunnableLambda(format_prompt_to_string, name="PromptToStringChain")
# Combine the chains
combined_chain = RunnableParallel(
extraction_chain=runnable,
prompt_string_chain=prompt_to_string_chain
) | RunnableLambda(extract_prompt_and_response, name="ExtractPromptAndResponse") | cleanlab_runnableWe have some product descriptions from Amazon Sales Dataset:
# Sample synthetic product catalog data from an Amazon-like dataset
synthetic_data = pd.DataFrame({
'description': [
'Echo Dot (3rd Gen) - Smart speaker with Alexa. Compact size, loud sound, and Bluetooth connectivity. Price: ₹4,499.',
'Enjoy powerful sound with the ZEBRONICS Zeb-Astra 20 Wireless BT v5.0 Portable Speaker. 10W RMS Output, TWS, 10H Battery Life. Priced at ₹2,299.',
'Zebronics ZEB-COUNTY 3W Wireless Bluetooth Portable Speaker - USB, SD Card, AUX, FM & Call Function. Price: ₹999.',
'Skybags Unisex Purple Oxford 10L Backpacks available for ₹1,000.',
'Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment. Price: ₹2,599.',
'Glowic Dual Compartment Canvas Laptop Backpack for Men and Women (Blue). Priced at ₹1,499.',
'Samsung Galaxy M33 5G - 6GB RAM, 128GB Storage, 6000mAh Battery, Travel Adapter included. Priced at ₹24,999.',
'OnePlus Nord CE 2 Lite 5G (Black Dusk) - 6GB RAM, 128GB Storage. Available for ₹19,999.',
'Redmi 10 Power - 8GB RAM, 128GB Storage, Sporty Orange color. Priced at ₹18,999.',
'boAt Airdopes 141 - Truly Wireless Earbuds, 42H Playtime, Beast Mode (Low Latency). Price: ₹3,995.',
'Apple 20W USB-C Power Adapter for iPhone, iPad & AirPods. Price: ₹1,900.',
'Fire-Boltt Ninja Call Pro Plus Smart Watch - 1.83" Display, Bluetooth Calling, AI Voice Assistance, 100 Sports Modes. Price: ₹19,999.',
'Samsung Galaxy M33 5G - 6GB RAM, 128GB Storage, Emerald Brown color, Travel Adapter included. Price: ₹24,999.',
'realme narzo 50A Prime - 4GB RAM, 64GB Storage, Full HD+ Display, 50MP AI Triple Camera. Priced at ₹13,499.',
'Redmi A1 - 2GB RAM, 32GB Storage, Light Blue color, AI Dual Cam, 5000mAh Battery. Price: ₹8,999.',
'OnePlus Nord CE 2 Lite 5G (Blue Tide) - 8GB RAM, 128GB Storage. Priced at ₹21,999.',
'boAt Airdopes Atom 81 - True Wireless Earbuds, 50H Playtime, Quad Mics, Beast Mode for Gaming. Price: ₹4,490.',
'boAt Airdopes 141 - True Wireless Earbuds, 42H Playtime, Beast Mode for Gaming. Price: ₹4,490.',
'boAt BassHeads 100 - In-Ear Wired Headphones with Mic (Black). Priced at ₹999.'
]
})
# Apply the chain to each data point and extract information
results = []
for idx, row in synthetic_data.iterrows():
result = combined_chain.invoke({"text": row['description']})
results.append(result)
# Extracting product information and transforming it into a DataFrame
extracted_products = []
for result in results:
response = result['response']
trustworthiness_score = result['trustworthiness_score']
product_data = response.dict()
product_data['trustworthiness_score'] = trustworthiness_score
extracted_products.append(product_data)
# Load the results into a DataFrame with each field as a column
extracted_df = pd.DataFrame(extracted_products) The chain was tested for GPT 3.5 Turbo and GPT 4 Omni.
Table
GPT 3.5 Turbo
| Name | Brand | Model | Specs | Price ₹ (in Rupees) | Trustworthiness Score |
|---|---|---|---|---|---|
| Echo Dot | 3rd Gen | Smart speaker with Alexa. Compact size, loud sound, and Bluetooth connectivity. | 4,499.00 | 0.85 | |
| ZEBRONICS Zeb-Astra 20 Wireless BT v5.0 Portable Speaker | 10W RMS Output, TWS, 10H Battery Life | 2,299.00 | 0.77 | ||
| ZEB-COUNTY 3W Wireless Bluetooth Portable Speaker | USB, SD Card, AUX, FM & Call Function | 999.00 | 0.74 | ||
| Skybags Unisex Purple Oxford 10L Backpack | Skybags | Oxford | 10L | 1,000.00 | 0.86 |
| Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment | 2,599.00 | 0.76 | |||
| Glowic Dual Compartment Canvas Laptop Backpack | Glowic | Dual Compartment | Color: Blue | 1,499.00 | 0.93 |
| Samsung Galaxy M33 5G | 6GB RAM, 128GB Storage, 6000mAh Battery, Travel Adapter included | 24,999.00 | 0.86 | ||
| OnePlus Nord CE 2 Lite 5G | 6GB RAM, 128GB Storage | 19,999.00 | 0.79 | ||
| Redmi 10 Power | 8GB RAM, 128GB Storage, Sporty Orange color | 18,999.00 | 0.79 | ||
| boAt Airdopes 141 | Truly Wireless Earbuds, 42H Playtime, Beast Mode (Low Latency) | 3,995.00 | 0.85 | ||
| 20W USB-C Power Adapter | Apple | 1,900.00 | 0.82 | ||
| Fire-Boltt Ninja Call Pro Plus Smart Watch | 1.83" Display, Bluetooth Calling, AI Voice Assistance, 100 Sports Modes | 19,999.00 | 0.8 | ||
| Samsung Galaxy M33 5G | 6GB RAM, 128GB Storage, Emerald Brown color, Travel Adapter included | 24,999.00 | 0.76 | ||
| realme narzo 50A Prime | 4GB RAM, 64GB Storage, Full HD+ Display, 50MP AI Triple Camera | 13,499.00 | 0.84 | ||
| Redmi A1 | 2GB RAM, 32GB Storage, Light Blue color, AI Dual Cam, 5000mAh Battery | 8,999.00 | 0.89 | ||
| OnePlus Nord CE 2 Lite 5G | 8GB RAM, 128GB Storage | 21,999.00 | 0.67 | ||
| boAt Airdopes Atom 81 | True Wireless Earbuds, 50H Playtime, Quad Mics, Beast Mode for Gaming | 4,490.00 | 0.75 | ||
| boAt Airdopes 141 | True Wireless Earbuds, 42H Playtime, Beast Mode for Gaming | 4,490.00 | 0.84 | ||
| boAt BassHeads 100 | In-Ear Wired Headphones with Mic (Black) | 999.00 | 0.83 |
The extracted data by GPT-4 omni yielded higher trustworthiness score and less null values for each product description.
Table
GPT-4o
| Name | Brand | Model | Specs | Price | Trustworthiness Score |
|---|---|---|---|---|---|
| Echo Dot (3rd Gen) | Amazon | Smart speaker with Alexa. Compact size, loud sound, and Bluetooth connectivity. | 4,499 | 0.92 | |
| ZEBRONICS Zeb-Astra 20 Wireless BT v5.0 Portable Speaker | ZEBRONICS | ZEBRONICS | 10W RMS Output, TWS, 10H Battery Life | 2,299 | 0.88 |
| ZEB-COUNTY 3W Wireless Bluetooth Portable Speaker | Zebronics | Zebronics | USB, SD Card, AUX, FM & Call Function | 999 | 0.79 |
| Skybags Unisex Purple Oxford 10L Backpack | Skybags | 1,000 | 0.66 | ||
| Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment | Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment | Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment | Trunkit Adventure Series 55L Water Resistance Trekking Hiking Travel Bag with Shoe Compartment | 2,599 | 0.78 |
| Glowic Dual Compartment Canvas Laptop Backpack for Men and Women (Blue) | Glowic | 1,499 | 0.77 | ||
| Samsung Galaxy M33 5G | Samsung | Galaxy M33 5G | 6GB RAM, 128GB Storage, 6000mAh Battery, Travel Adapter included | 24,999 | 0.84 |
| OnePlus Nord CE 2 Lite 5G | OnePlus | 6GB RAM, 128GB Storage | 19,999 | 0.75 | |
| Redmi 10 Power | Redmi | 8GB RAM, 128GB Storage, Sporty Orange color | 18,999 | 0.82 | |
| boAt Airdopes 141 | boAt | Truly Wireless Earbuds, 42H Playtime, Beast Mode (Low Latency) | 3,995 | 0.87 | |
| 20W USB-C Power Adapter | Apple | 1,900 | 0.82 | ||
| Fire-Boltt Ninja Call Pro Plus Smart Watch | Fire-Boltt | 1.83" Display, Bluetooth Calling, AI Voice Assistance, 100 Sports Modes | 19,999 | 0.8 | |
| Samsung Galaxy M33 5G | Samsung | Galaxy M33 5G | 6GB RAM, 128GB Storage, Emerald Brown color, Travel Adapter included | 24,999 | 0.87 |
| realme narzo 50A Prime | realme | narzo 50A Prime | 4GB RAM, 64GB Storage, Full HD+ Display, 50MP AI Triple Camera | 13,499 | 0.93 |
| Redmi A1 | Redmi | 2GB RAM, 32GB Storage, Light Blue color, AI Dual Cam, 5000mAh Battery | 8,999 | 0.91 | |
| OnePlus Nord CE 2 Lite 5G | OnePlus | Nord CE 2 Lite 5G | 8GB RAM, 128GB Storage | 21,999 | 0.87 |
| boAt Airdopes Atom 81 | boAt | True Wireless Earbuds, 50H Playtime, Quad Mics, Beast Mode for Gaming | 4,490 | 0.87 | |
| boAt Airdopes 141 | boAt | True Wireless Earbuds, 42H Playtime, Beast Mode for Gaming | 4,490 | 0.87 | |
| boAt BassHeads 100 - In-Ear Wired Headphones with Mic | boAt | BassHeads 100 | In-Ear, Wired, With Mic, Color: Black | 999 | 0.87 |
Takeaways
An LLM functions like an interpolative database, allowing you to query information stored in its training data using natural language. It can retrieve not only the data it was trained on, but also the arbitrary combinations of that data. However, when queried with poorly phrased prompts or questions that cannot be answered directly from its training data, the LLM is forced to generate responses that seem fit to the query. This is where hallucinations might occur. Whether hallucinations are a bug or a feature is debatable, but in some cases this nature of LLM can help handling imprecise prompts from users, ultimately providing the information they need despite of poorly phrased queries. Instances of LLM hallucinations have led to real-world issues like misleading customers with incorrect information, so identifying when LLM hallucinates is a crucial strategy for deploying trustworthy language models. Confidence and consistency are two key dimensions we can explore the assess the trustworthiness of the model’s responses. Confidence involves the model expressing uncertainty about its answers, which helps in gauging the reliability of the response. Consistency checks involve comparing multiple responses to the same prompt to identify potential contradictions, indicating possible hallucinations. The use of trustworthiness scores can guide the deployment of AI systems, ensuring that responses are not only accurate but also reliable and trustworthy. This is particularly important for applications where users depend on the correctness of the information provided.
Resources
- Paper Resources: https://github.com/jxzhangjhu/Awesome-LLM-Uncertainty-Reliability-Robustness
- Teaching Models to express their uncertainty in words https://openai.com/index/teaching-models-to-express-their-uncertainty-in-words/?fbclid=IwAR1pvvhKegivwZQVa1vz-yzjs51PdUB_5MZ67KqzDA4znhX3iNId_VzDmq0
- Methodology Review: Can We Detect LLM Hallucinations? NannyML https://www.nannyml.com/blog/llm-hallucination-detection
- SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models (2024) Intuit AI https://medium.com/intuit-engineering/intuit-presents-innovative-approach-to-quantifying-llm-uncertainty-at-eacl-2024-f839a8f1b89b
- Quantifying Uncertainty in Answers from Any Language Model and Enhancing their Trustworthiness (Oct 2023) Cleanlabs https://arxiv.org/pdf/2308.16175
About the Authors
White Widget AI and Data Science Team excels in leveraging technologies such as machine learning, natural language processing, and generative AI, developing innovative solutions for the publishing, media, and entertainment industries—from crafting AI-driven games to enhancing public discourse and strategic decision-making through robust data analytics.
Primary Author
Jermaine P. a data engineer who focuses on emerging developments in AI and machine learning. A researcher and university educator, he's co-authored multiple papers on the subject, with special attention to NLP, semantic networks, and enhancing AI models using various techniques.
Contributors
Andrea L. brings over two decades of expertise in software engineering, product design, and cybersecurity to her role as Chief Technical Officer at White Widget.
Albert D. a data engineer who excels in AI-driven data analysis, system optimization, and meticulous adherence to best practices. He particularly excels in semantic engineering, transport and geospatial data analysis.