Article
How the Best Companies Actually Build Intelligence: The Secrets Behind High-Volume Knowledge Graphs
Last Updated on October 7, 2025
by White Widget AI and Data Science Team

BoliviaInteligente | Unsplash
Build a Knowledge Graph that actually works.
Trillion-Dollar Secret: How Knowledge Graphs Separate Real AI from Expensive Autocomplete
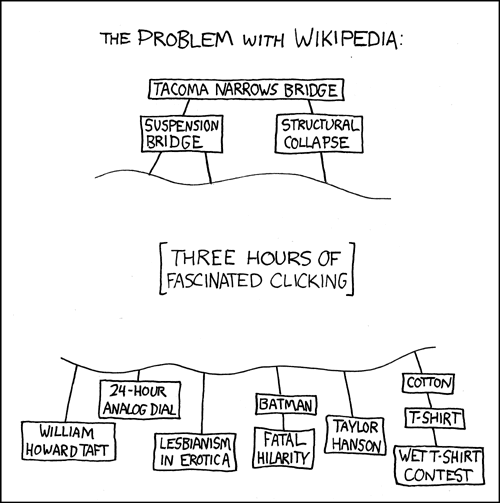
Yes, graphs power everything from Netflix to Wikipedia (xkcd.com)
OpenAI's o1 achieves 74% on mathematical olympiad problems. Google's AlphaFold 3 predicts molecular interactions with unprecedented accuracy, revolutionizing drug discovery. TikTok's algorithm processes over one billion video views per day with terrifyingly accurate recommendations. Their secret? Knowledge graphs that obliterate the gap between data and intelligence. 2025 reality: Knowledge graphs enable AI systems to reason, adapt, explain, and improve continuously through distributed architectures. The engineering principles aren't classified—the scaling lessons, distributed graph consistency, battle-tested semantic reasoning architectures—all learnable. All buildable. Time to build neural knowledge that thinks.
What are Knowledge Graphs good at?
A Knowledge Graph (KG) represents data as a network of entities—each with its own properties and relationships—enabling flexible querying over complex, interrelated domains. Unlike rigid tabular formats or document stores, KGs naturally preserve context: they let you model "who is what to whom" in a way that's both human-readable and machine-tractable.
They’re particularly powerful when you're working across datasets that differ in structure, vocabulary, and granularity. Whether you're trying to reconcile conflicting entries in your CRM, trace the provenance of a shipping container across systems, or link research papers to gene targets, KGs make it possible to bring everything into one coherent, queryable whole. This unlocks downstream applications like transforming structured data into intuitive insights via Natural Language Generation and acting as an LLM’s knowledge base for Retrieval-Augmented Generation (RAG), an emerging technique called GraphRAG.
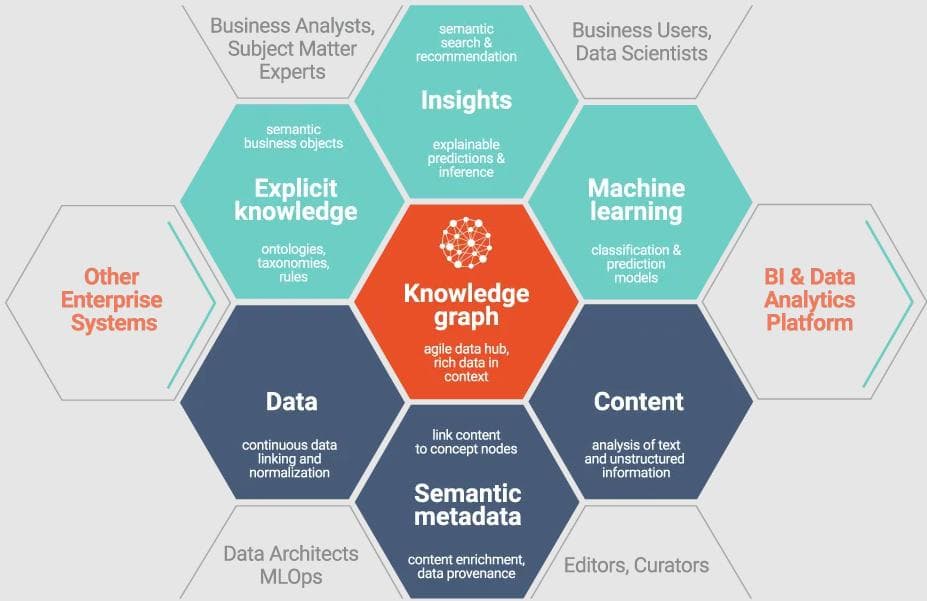
Source: Graphwise
What are the challenges in implementing a Knowledge Graph?
The flexibility that makes KGs so appealing also makes them dangerously easy to overcomplicate. Without clear design principles, it's easy to fall into traps: inventing properties when standards exist, merging incompatible ontologies, or letting your schema balloon into unnecessary minutiae.
Here are some unique challenges when building Knowledge Graphs, distilled from our experience iterating across different tech stacks, particularly leveraging Graphwise GraphDB:
- Too many custom properties. It’s tempting to build your ontology from the ground up, tailored to exactly your organization’s needs. After a bit of research, though, you might find that there are existing standards that already contain the definitions you need, and you’ll need to align your data with those standards instead.
- Duplicate properties from external ontologies. If you’re integrating external ontologies with overlapping domains, they will have overlapping properties representing the same real-world information.
- Changing data across time. This is a question of policy: do you delete data once it’s been invalidated, or have an indicator that a value has been superseded?
- How do you uniquely identify your entities, without collision? Can entities have multiple identifiers?
With the expressiveness and flexibility of Knowledge Graphs, you will want to plan ahead to keep it focused and clearly connected.
How do I build an Ontology for scale?
What’s an Ontology?
The ontology is the vocabulary—classes, properties, and relationships—that says:
- what kinds of things exist in this graph (e.g.
Bus,Route,Stop) - which identifiers are considered authoritative (
busId,licensePlate,contractNumber) - and their connections (
operatesRoute,stopsAt)
This defines the space of all that can possibly exist in your Knowledge Graph.
Source: Graphwise
How do I plan my ontology?
The first step in building your Knowledge Graph is laying out what data you have, and what specific questions you want it to answer. These are your competency questions.
Competency questions are a practical design tool used during the development of an ontology or Knowledge Graph. They're essentially a set of sample questions that your graph should be able to answer once it's built.For example:
- “Which Euro 6 diesel buses will exceed their maintenance window next month?”
- “How many routes are affected by the closure of this terminal?”
Then, try to answer the questions using pseudocode (or even outright SPARQL) queries to validate:
SELECT ?bus ?plate
WHERE {
?bus a :Bus ;
:licensePlate ?plate ;
:emissionClass "EURO_6" ;
:dueForService ?date .
FILTER (?date < "2025-07-01")
}The query returns the Knowledge Graph ID and a human-readable license plate that answers the question. If you can’t express it as a query, your ontology is still missing a class, property, or relationship!
Can I use existing Ontologies?
You can integrate existing ontologies with your own custom ontology.
Schema.org is widely supported and is fairly extensive—it’s likely that most of what you need is already defined under it, especially if you intend to use this as metadata for the web.
Prioritize using schema.org properties instead of defining your own, where possible.
For specialized needs, check if there are existing published ontologies that can be reused, even if it’s just for specific concepts. For example, the Organization Ontology captures the founding, reorganization, and succession between organizations across time.
Be mindful of similar-sounding but distinct definitions, making sure to either explicitly equate them, or work with the appropriate one:
owl:Thingandschema:Thingare differentowl:sameAsandschema:sameAsare different
If you’re using a reasoning engine, the owl: predicates will typically be the ones your reasoning engine expects.
What is the right level of detail for my Ontology?
Everything can be modeled, and you’ll never run out of things to define. Keep it simple.
Not everything needs to be modeled, just enough to answer your competency questions. It remains an option to expand the ontology as needs arise and as more data becomes available.
This can be related to the concept of parsimony in statistical models, where a simpler model is preferred over one with more variables, if both of them fit the data similarly well.
Can I use multiple external ontologies?
Yes, but keep in mind trade-offs in complexity, redundancy, and performance.
Multiple ontologies often have overlapping definitions for common concepts, e.g. foaf:Person and schema:Person. In practice, if you integrate foaf:Person and schema:Person linked by owl:equivalentClass what will happen is that every Person entity will now have two triples. If you also have the Follow the Money ontology, you also have ftm:Person which is a subclass of ftm:LegalEntity and a host of other inferences.
While semantically correct, and potentially very useful, this can easily add a lot of triples, computational overhead and visual noise from these redundant definitions, making it harder to isolate the actual distinct classes of an entity.
Keep it simple:
- don’t integrate external ontologies until you know there’s something in it that you absolutely need
- it may be sufficient to only integrate a subset of that external ontology
How do I model things vs. references to things?
When modeling a domain, take care to distinguish whether you are dealing with something that is simply a reference to or symbol of another entity, especially when you have both in the same knowledge graph. As the saying goes: “The map is not the territory.” To illustrate:
- Is a website topic
Mexicothe same as the place namedMexico?Consequence: If the website topic name is modified, e.g.Mexico, Pampangato disambiguate it from the country, you should take care not to accidentally imply that the real-life municipality’s name isMexico, Pampanga. - Is the reference to a car on a document (like a shipping manifest) the same as the car itself?
Consequence: If you have a
schema:dateModifiedfield, does it refer to the date that the shipping manifest was updated, or the date the car was repainted?
Properties like schema:about and schema:mainEntity can be used to connect the Topic entity to the Place entity, where:
- the Topic has its schema:URL pointing to your website, while
- the Place has own real-world properties like schema:PostalAddress
How do I model properties that change over time?

Some attributes like height are continuously changing!
Entity attributes, like schema:height, can change across time, as can relations like schema:spouse, and it depends on your needs to determine whether this can be simplified to a single value.
If they remarry, do you replace the old value with the new one, or do you need to keep both values?
Do you need a way to track which spouse is the current one, or the period during which they were married?
These questions inform you whether to use a simple property, or to create an entity like a custom:marriage property, with its own start and end date properties, linked to the two Person entities.
The schema:Observation class exactly captures the way entity data can change across time, with each point in time existing as its own entity in your Knowledge Graph.
Identifiers and Lookup
How can I generate unique IDs for my entities?
For rich domains that combine many bulk data sources, especially those in natural language (e.g. media reports), you need a way to create identifiers that are guaranteed to be unique. This immediately rules out using names, which commonly overlap. Is “Amazon” the company, the rainforest, or the river?
Table
Comparison of ID Generation Techniques
| Method | Length | Alphabet | Semanticity | Independence | Ease of Generation | Example |
|---|---|---|---|---|---|---|
| UUID | 32 | Case-insensitive hexadecimal (0-9, A-F) | None | Yes | Easy | bec9b1e6-8cae-42aa-b1e9-f70bc46bfddd |
| Random Number | At least 10 | Numbers | None | Yes | Very Easy | 4519753869 |
| Random String | At least 6 | Case-insensitive numbers and letters and optionally a symbol | None | Yes | Easy | a2n59muv |
| Incremental | Depends on number of entities, can be as short as 5 | Numbers with optional case-insensitive letters | None | No | Tricky | 000082 |
| Hierarchical | Depends on complexity, can be as short as 8 | Depends, can be the same as Random String; can be letter prefix based on type, then numeric for the rest of the ID | Depends | No | Complex | B514957287 |
Each technique has its own implications on uniqueness, human readability, and security. Incremental IDs, for example, can leak information about your knowledge graph size, while UUIDs are long and take up space.
Not everything needs to have a generated ID. For example, if you've already generated an entity foo:B1234567 and you're making an entity that's dependent on that (in the sense that it's only meaningful given the context of the primary entity), you can make an identifier based on the primary entity, like foo:B1234567-writeup.
How do I deal with multiple identifiers for the same Person?

Entities can have multiple identifiers, all valid.
Eventually, you will discover that “John S.” (id: 008521) from a social media dataset and “Smith, John” (id: 016331) from a financial filing are the same person. You connect them with owl:sameAs. Now you have one Person with two IDs, both valid and correct. What then?
A way to handle this situation is to designate a canonical identifier; all other identifiers remain correct and usable, but are to be treated as essentially redirects or aliases for the canonical identifier. This makes it possible to bulk-replace non-canonical identifiers in subsequent usage and guarantee consistency in the final value.
This is important when you want to export to tabular formats (e.g. when working with them on spreadsheets) where you need to pick just one value to put in your cell.
Graph Organization
What is a Named Graph, and how is it used?
A named graph is a way of grouping your graph’s triples under a shared identifier, and gives you a way to refer to just that distinct part of the Knowledge Graph. Each triple is tagged with another identifier, a fourth column that says, “this fact came from here”.
The graph URI can represent different things:
- a dataset (e.g.
/source/profiles) - a domain (
/people) - a processing stage (
/raw/2025/06,/cleaned/2025)
These are useful tools for organizing and compartmentalizing our data, and operations like querying or deletion can be scoped to work only on specific named graphs.
Pros of having multiple graphs:
- easy to drop individual subgraphs without affecting the rest of the data
- for example, a single file or sheet was changed
- this minimizes the scale of reinference needed
- easy to contextualize provenance - can use a subgraph to trace back to a given dataset or domain
Cons to watch out for:
- you need to remember what they were for
- these need to be documented, maintained, and cascaded to the team
- duplicated triples across subgraphs
How do I manage multiple subgraphs?
One way to manage the scale of multiple subgraphs is to merge them once active work is complete.
For example, if a project milestone contains datasets for:
- company profiles
- financial statistics published by companies
- news reports about companies of interest
It can be useful to keep these separate in their own graphs while work is active and ingest files are being iterated upon for tweaking. Once the data has been polished and the milestone delivered, the subgraphs can be merged into a single named graph for corporate data. This method is analogous to source code management workflows where rapid iteration occurs on feature branches, which are then merged into the main branch once it’s time to ship.
How do I use Structured Data for SEO?
Schema.org is already commonly compatible with search engines for parsing data in a way that enables enhanced presentation in search results, like rich snippets and carousels, typically read from embedded JSON-LD on the page. When publishing structured data for SEO, keep in mind that not everything in Schema.org is actually being read by downstream consumers like Google. You can check the supported templates and Google’s Rich Results Test, or equivalents like Bing’s Structured Data documentation, to avoid wasting bandwidth on fields that will never be read. Consumer support evolves over time; properties unsupported today might become critical later. Maintain structured data flexibility, document your schema choices clearly, and periodically audit your markup to adapt swiftly when consumer capabilities change.
Linking Everything Together
Knowledge Graphs have the transformative potential to unify your data silos, resolve ambiguity, and empower your teams to rapidly uncover actionable insights. However, the real benefits depend on thoughtful design, clear ontology, and proactive management. By adhering to these best practices, you'll build a resilient graph infrastructure that's ready to scale with your organization's evolving needs.
Want to build a digital brain? We’ll help you
Done reading about knowledge graphs and ready to actually build one that doesn't collapse under real-world pressure? White Widget turns 'this should be simple' into 'OMG amazing it actually works.' Talk to us—we have ontologists, AI & ML specialists and custom software builders that can speak fluent graph theory and deploy real enterprise in-production systems.
About the Authors
White Widget AI and Data Science Team excels in leveraging technologies such as machine learning, natural language processing, and generative AI, developing innovative solutions for the publishing, media, and entertainment industries—from crafting AI-driven games to enhancing public discourse and strategic decision-making through robust data analytics.
Primary Author
Albert D. a data engineer who excels in AI-driven data analysis, system optimization, and meticulous adherence to best practices. He particularly excels in semantic engineering, transport and geospatial data analysis.