Article
The Road to Trustworthy LLMs: How to Leverage Retrieval-Augmented Generation
Last Updated on October 7, 2025
by White Widget AI and Data Science Team

White Widget Team
Do you want to build tech that’s harder, better, faster, stronger?
The Problem
Large Language Models, despite their wide capabilities and applications, face challenges that limit their effectiveness in different situations. They've got a cutoff point for what they know, and sometimes their info isn't up-to-the-minute. They can get things wrong or even make stuff up, and won't always give you answers that fit just right unless they're steered with the right context. To address these drawbacks of LLMs, we can incorporate factual information when they answer questions. Different techniques are:
- Prompt Engineering
- Retrieval-Augmented Generation
- Providing tools for LLMs to use as "Agents", such as search engines or 3rd-party APIs
To understand these techniques, we can borrow concepts from how Central Processing Units utilize memory. Foundation models, like computers, are designed to be general-purpose, giving us the ability extend their capabilities and functions. Aptly named, they are designed to be customised to better suit your tasks’ needs (more on this later). Foundation models have parametric memory called model weights, and Large Language Models use this to generate contextually-relevant text. But these models have a limitation called context length, which is the amount of text a model can remember and generate.
Just like in computer hardware, where increasing the memory space that CPUs have does not actually guarantee better performance, LLMs with wider context lengths are found to be less effective than retrieval-based approaches in some applications.
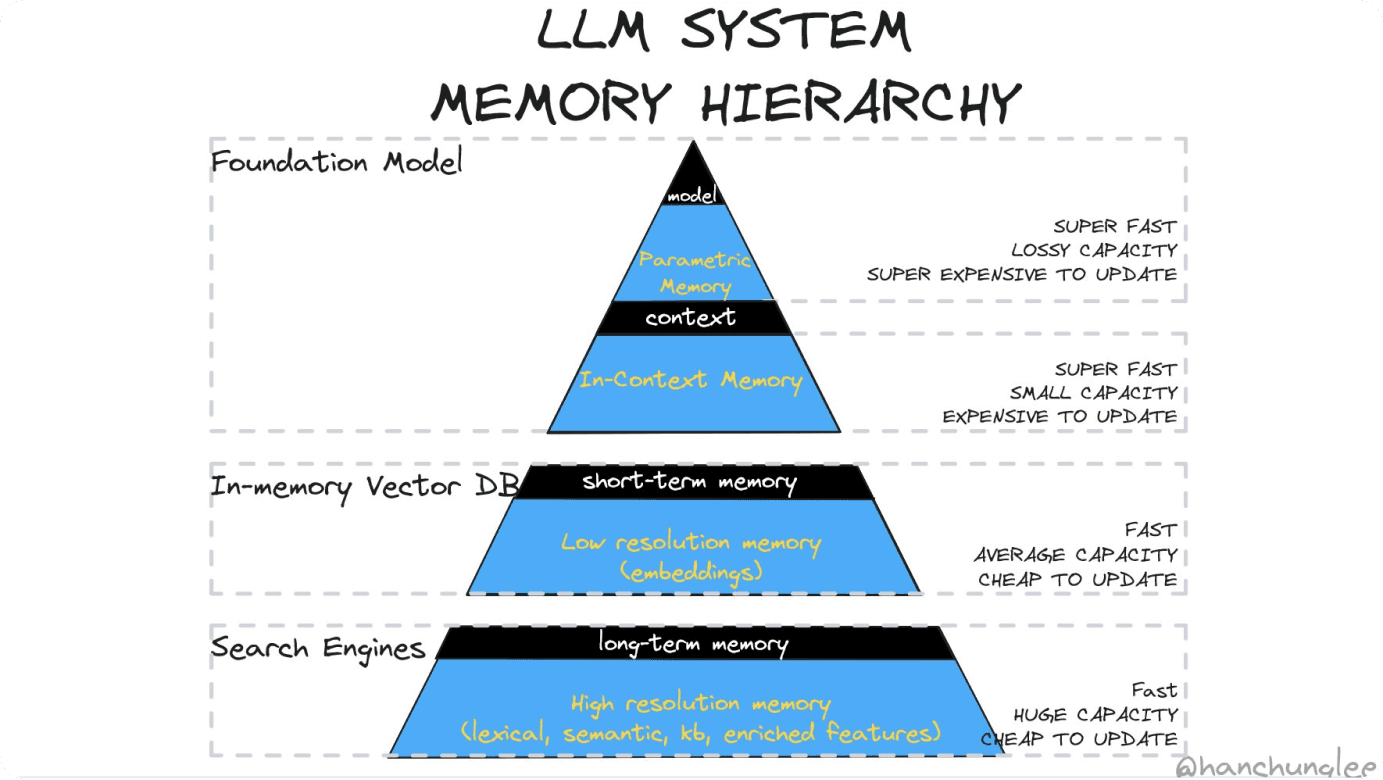
Fig. 1: LLM System Memory Hierarchy. Credits to Han Lee for the Image
To understand the different techniques of extending LLM capabilities, we can borrow the idea of memory hierarchy from computers. Computers are designed with general-purpose minimal instruction sets that can perform primitive calculations, so they can respond to a given input. Large Language Models, are trained with model weights which represent language, and they can be trained to generate dynamic responses based on given text.
Prompt Engineering can be thought of as designing our own registers by giving them specific, step-by-step instructions on how to perform complex tasks.
Databases like Vector DBs can be thought of as secondary storage where we store documents and data for future use. The process of saving and loading files for future use is known as Retrieval-Augmented Generation.
Enormous information and knowledge bases can be made available to public and information can be retrieved with the help of external sources like Search Engines, and large language models can be designed to query search engines.
What is a Foundation Model?
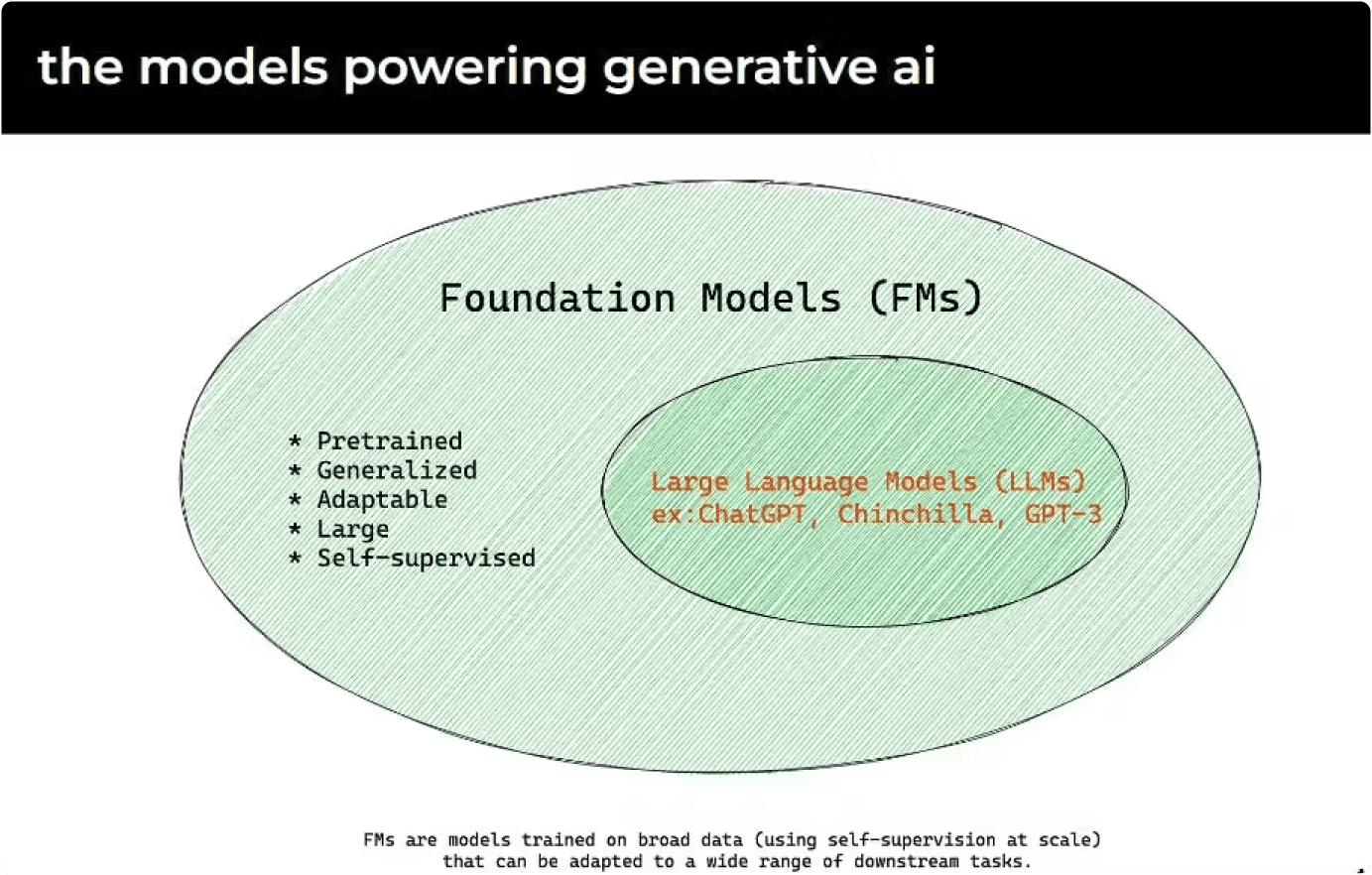
Image credits to Armand of nocode.ai
Foundation models are a class of models that include Large Language Models for understanding and generating content across modalities. Large Language Models are specific to language tasks, and there are other models designed for images and audio. The term is used to highlight the potential of these models as a base for developing applications across various domains.
How Large Language Models Work
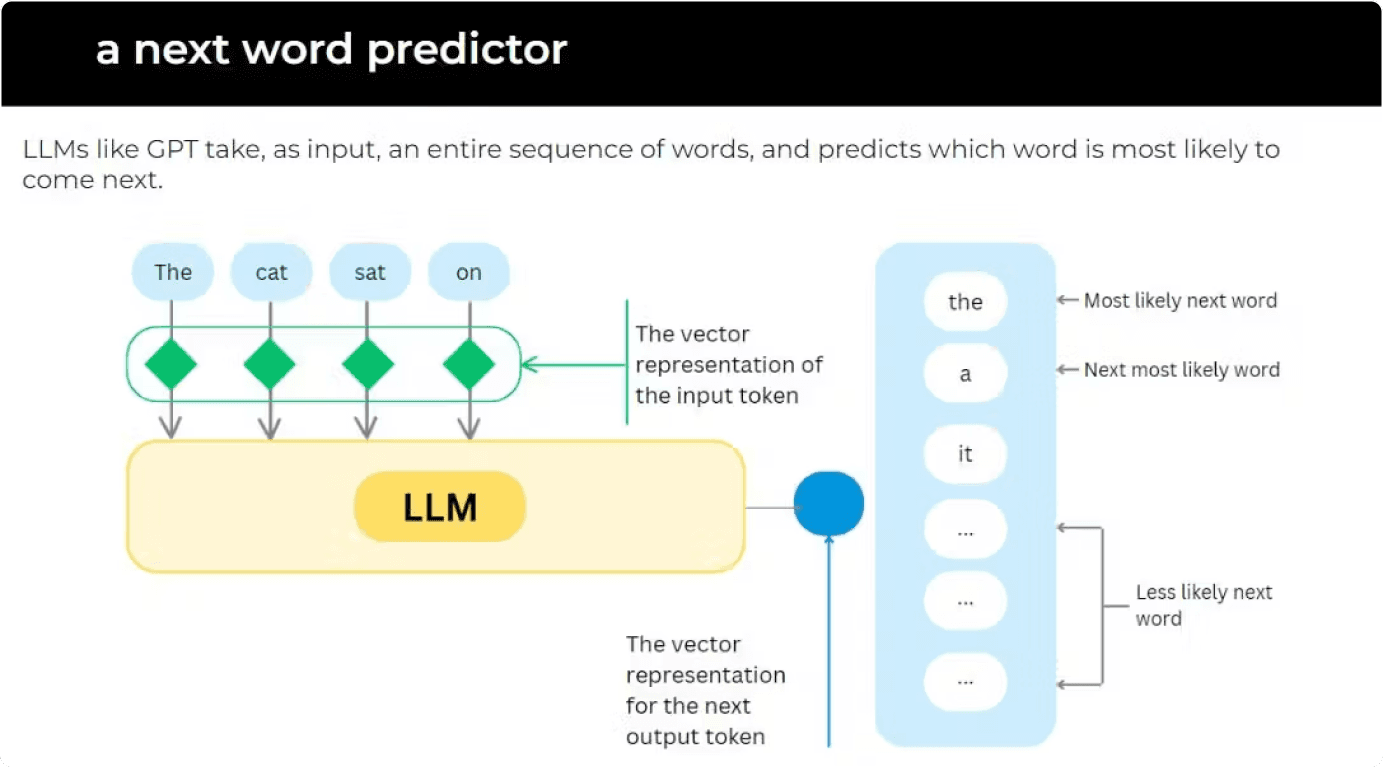
Image credits to Armand of nocode.ai
When you ask LLMs like ChatGPT a question, several steps happen. Let’s consider this example where we ask the LLM a simple question. Question: What is the capital of France? First, your question or sentences get chunked into tokens. A token can be thought of as a set of text characters, and there are many ways to tokenize a sentence, but let’s settle with the obvious way, and tokenize our sentences into words for now. Each of the tokens then will be converted into vectors of numbers, these are called embeddings. The embeddings can then be passed to the language model. The language model has a rectangular array of numbers called weight matrices, which represents all of the data the model has been trained on. You can think of the weight matrices as inherent knowledge the language model has and will use to process the embeddings, using Matrix-Vector multiplication! Note that a large model can have hundreds of billions of model weights, all used to multiply the embeddings of the question we have. By the end of this multiplication, we then get another vector of numbers, this time representing the probability of the next likely token to your question. From embeddings then, the tokens get stitched into texts, hoping that it answers or gets the relevant information that you need. Think of it like playing the game where we have to fill in the blanks. For example, think of the partial statement, “The number 2 when multiplied by 2, ______________.” We then predict that the next set of words could be: a. the product is 4. b. the answer is 4. c. is 4. In our case, when we ask “What is the capital of France?”, the next set of words could be “the capital of France is Paris”. Because the LLM is autocompleting the right answer, and because variations of the most probable responses tend to gravitate towards this being the answer, it will say that this is the answer. It might phrase it differently, but it has no idea of what is right or wrong, just what is probably the correct response based on the data it has been fed.
Let’s say we want to make LLMs work on our own data for different use cases like summarization and automation. We need a way to store this data into memory and make it available for LLMs to retrieve, just like our computers when we're accessing our files. The process of saving and loading files for future use is known as Retrieval-Augmented Generation (RAG).
Short Overview of RAG
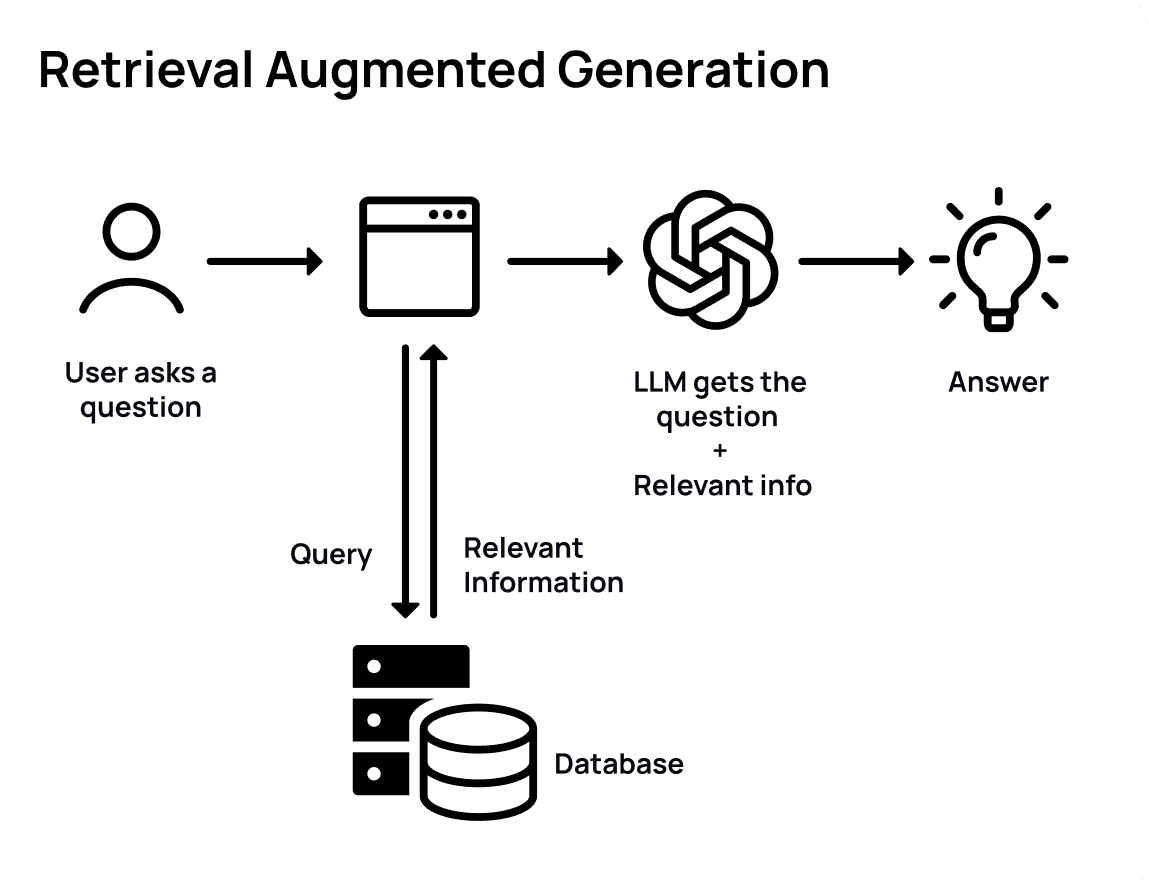
Fig 2: How RAG answers a question
RAG is a method used in AI to help it answer questions better. It does this by first finding relevant information from a big collection of texts and then using that information to come up with an answer. This way, the AI can give responses that are not only based on what it already knows but also on new, specific details it finds each time it's asked a question.
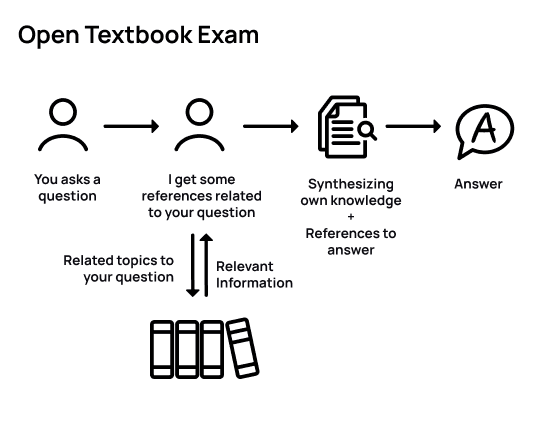
Fig 3: RAG is analogous to human taking an open-textbook exam
RAG is like how someone answers questions in an exam where they can use their textbooks and references. Imagine you ask me something. First, I would search for information and topics in the textbook that are related to your question. Then, I would understand what I found and organize it in my mind. Finally, I would give you an answer based on what I learned from the textbook.
How Data is Loaded and Represented
Vector Database
Typically, RAG workflows store documents in a vector database. A vector database is a collection of high-dimensional vectors that represent entities or concepts, such as words, phrases or documents. The numbers encode how concepts are related to one another. Then we can get related topics using distance-based calculations to vectors.
Why do we need to represent documents?
Computer software like LLMs cannot interpret documents the way humans do right away. To help them, we turn the information in the documents into a form that computers can work with. This usually means converting words and sentences into numbers or patterns that the computer can recognize and analyze. This process allows computers to "read" and use the information in the documents to answer questions, make decisions, or learn new things. Vector representation is one way to help LLMs to understand your documents and file.
This means we turn documents into vectors by turning each word of a document into numbers based on how often they appear statistically. The most popular technique is by creating embeddings, a machine learning technique where a model learns relationships between concepts in an automated manner. This helps computers to understand and compare different documents easily.

Fig 4: Concepts are encoded into vectors that a model can understand. Relatedness of concepts can be measured by how close their vector representations are.
Embedding is the process of learning how concepts are related in an automated manner using machine learning models. As vectors, concepts can be related by measuring the distance between them, or angular distance between them (e.g., cosine similarity)
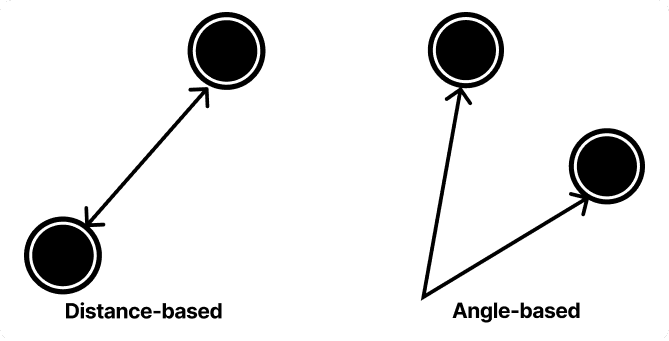
Fig 5: How “close” the concepts are can be done in two different ways: measured based on the distance between two vectors, or the angle of separation between them.
Vector databases allow us to measure the similarity or relatedness between concepts or entities, based on their vector representations. For example, a vector database can tell that an apple and an orange are related to fruit. But at a glance, it is hard to tell how these vectors are related, and you’d need to perform similarity calculations to uncover their relationships.
Limitations of using Vector Databases
The problem with vectors is that it is hard to visualize what the related concepts are. To reveal the topics close to an “apple”, we need to compare that concept with all existing concepts in a vector database before we can tell you the concepts most related to apples. Another limitation with vectors is that we cannot see how relationships between concepts gets formed. It's a mysterious and unreliable black box which we can't see inside or make it explain how it came to those conclusions, which can make the conclusions it jumps to dangerous and unpredictable. Lastly, updating a document is expensive in a Vector Database: updating a document means we have to recompute the vector that represents it, which is why OpenAI had the disclaimer that it has a knowledge limit up to a certain point in time.
Graph Database
Another way we can represent concepts and entities is through the use of knowledge graphs stored in a graph database. A knowledge graph consists of points (nodes) and lines (edges) that show how different concepts and items relate to each other, including their facts, characteristics, or categories.
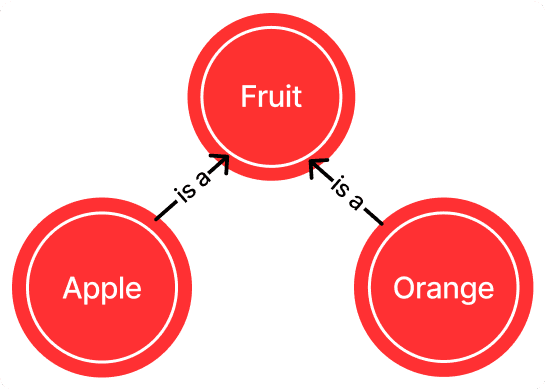
Fig 6: A knowledge graph consists of points (nodes) and lines (edges) that show how different concepts and items relate to each other, including their facts, characteristics, or categories.
Here is an example of a knowledge graph with nodes representing ‘Fruit’, ‘Apple’ and ‘Orange’. The nodes are points that stand for concepts, and the lines, or edges, connect these nodes and describe their relationship. Just like in the case of vector databases, the knowledge graph can tell how too how these concepts are related. But this representation explicitly tell us that apple and orange are related by showing that they both come under the broader category of ‘Fruit’.
Preciseness of Knowledge Graphs
As shown in the example, knowledge graphs can provide more precise and specific information than vector databases. Vector database can only tell us how similar or how related the concepts are, but not the kind of relationship they have. On other hand, knowledge graphs can tell us the exact type and direction of the relationship.
Instead of vectors, we extract entities and concepts, as well as their relationships, from a given document. Graph database stores them as triples:
concept 1 - [:relationship] -> concept 2
Apple - [:is_a] -> Fruit
Orange - [:is_a] -> Fruit
Supermarket - [:sells] -> Fruit
...
Unlike in vector databases, the insertion and updating of a node or relationship can be made much easier, without any need for recomputes or having to compute an embedding from a model.
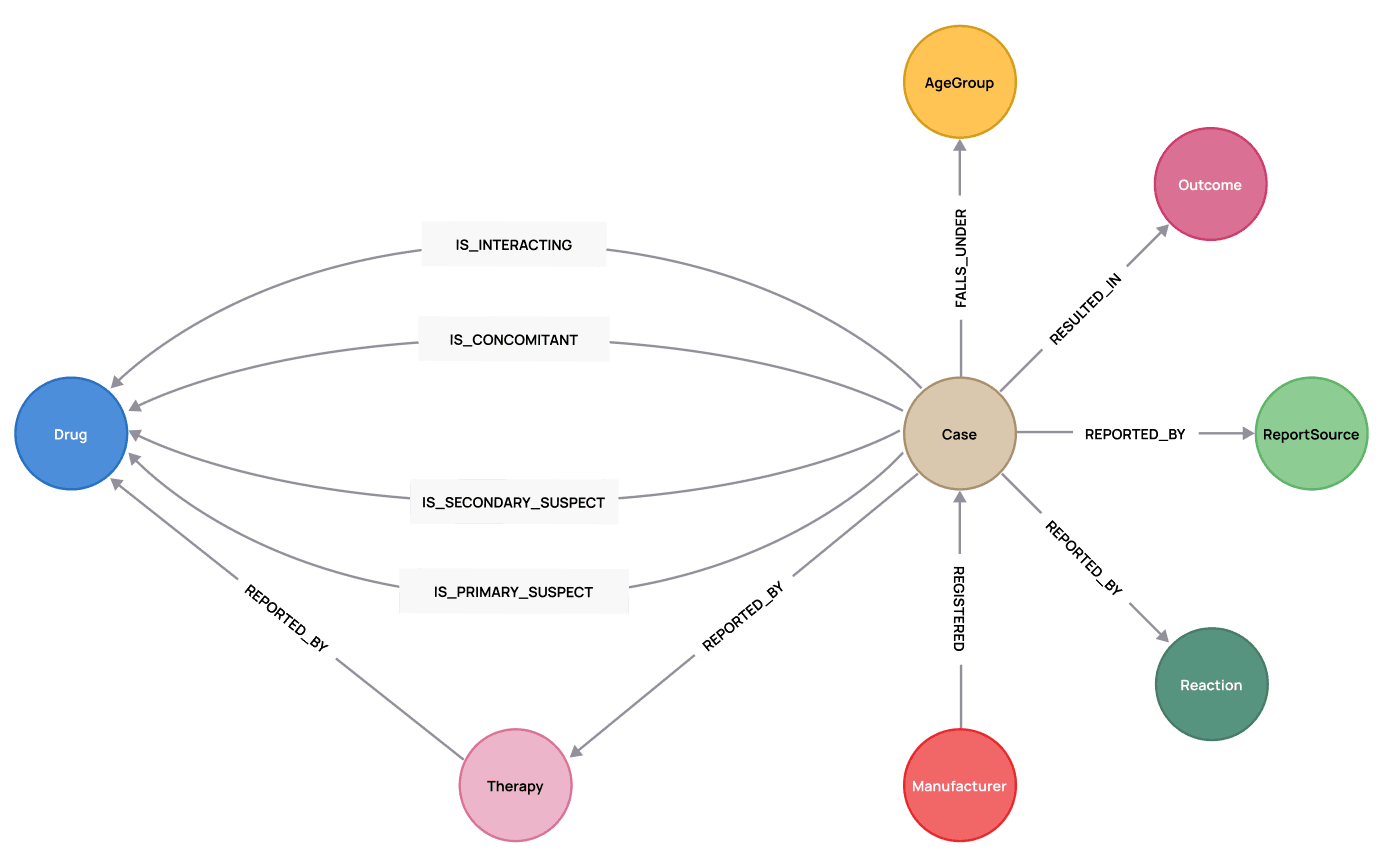
Fig 7: Example Data Model of FDA Adverse Event Reporting System (FAERS) Data from Neo4j
When we ask a question, an LLM can turn the question into a graph database query and then use the query results as context, in order to generate answers for the given question.
Limitations of using Graph Databases
The problem with using graph databases is that LLMs generate the query based on the given question. This could pose risks that will need proper planning to avoid:
- Issues with Data Integrity: LLMs might unintentionally modify or delete data if not properly controlled.
- Performance: LLMs might hallucinate incorrect queries which can be handled and incrementally improved, but more frequent or complex queries might lead to performance slowdowns, affecting the responsiveness of the database.
- Unpredictable Behavior: The unpredictable nature of queries generated by LLMs might lead to unexpected results, making it hard to anticipate and manage database behavior.
Unlike vector databases, in graph databases we need to define the schema and relationships between entities, but LLMs can also help with the entity extraction process too, during the creation of graphs. Just like humans who can only work with what they have, LLMs may also struggle with querying low quality. To control for this behavior, we can incorporate prompt engineering techniques to give the LLMs access to details that will make the querying process much easier. Here are the things we could share with the LLM:
- Give the schema of the data model.
- Give it (or grant the ability to access) the data definitions and documentations for the data model.
- Give the metric definitions and structured business questions that the LLM is allowed to ask. A principle of proper AI integration design is that LLMs are given the least privilege needed to perform queries (e.g., only reads are allowed).
- Grant role-based access on concepts and relationships that can be queried by LLMs. The nature of graph representation makes this kind of access much easier to model than vector databases.
Finally, support for complex queries can be introduced either by fine-tuning model weights (re-writing some parts of your Foundation Model), or by using prompt engineering. This emphasizes that LLMs should not do queries freestyle, and we must give them more context to increase the likelihood of getting answers right. For example, we can prepare templates and questions that can be asked from the given data. (Related: templates for increased success in natural language generation)
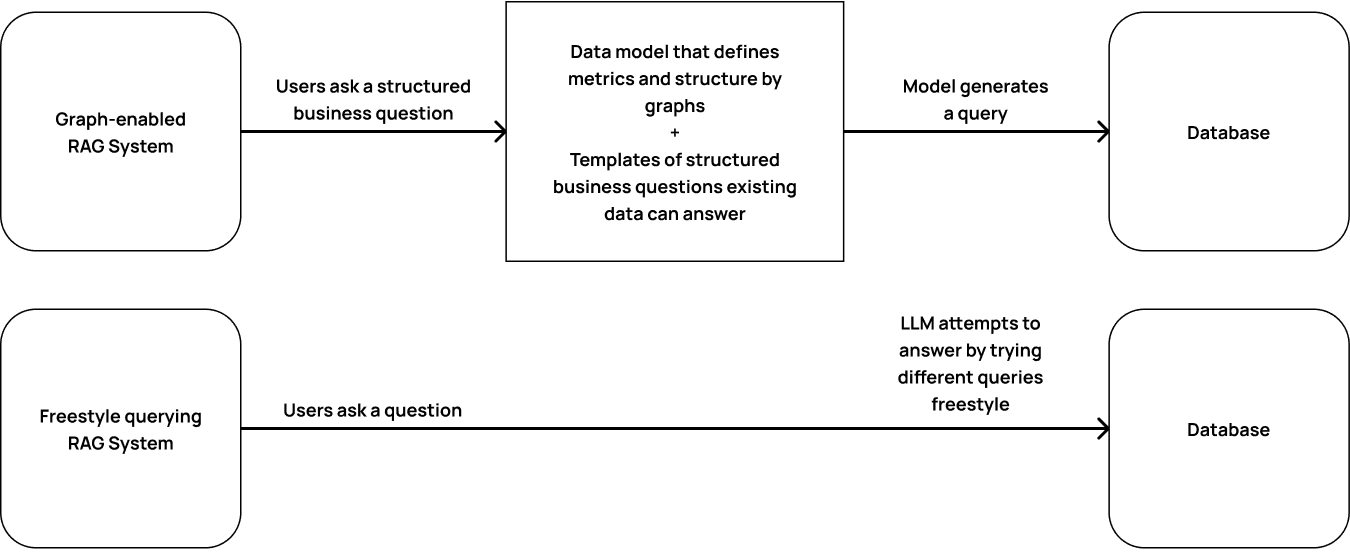
Fig 8: Image adapted from Ben Stancil
This point also highlights that LLMs can provide a better interface for querying data and answering questions related to it, but they will not as a total replacement for analysts, as there will still be a gap between turning novel business questions into full queries. It will still need custom implementation but it will really empower your analyst and management teams to do more with data than they ever have before.
Conclusion
Large Language Models can excel both in general and domain-specific applications. Just like your computer, where a lot of the work is not just carried out by the CPU, but also by the RAM, we can address LLM’s limitations by borrowing the idea of memory hierarchy from computer architecture and using techniques like Prompt Engineering and Retrieval-Augmented Generation to design our LLM systems.
In this article, we have focused on what Retrieval-Augmented Generation is, the limitations of vector databases as our usual secondary memory storage for data, and how knowledge graphs can act as intermediary for both LLMs and humans to query data. Knowledge Graphs also act as a secondary memory storage for data, which unlocks a crucial need for AI models: the transparency and verifiability of what LLMs use to answer a question. We have also tackled some graph database limitations and how best to work with them.
LLMs powered with our own data have massive potential and can provide a superior experience in extracting insights from data. Soon, we might see a future where AI models can understand customers’ needs and adapt, and software can sell outcomes rather than tools. But it will be difficult to reach that safer AI future if we lack a reliable and true representation of knowledge that both machines and humans can understand, and this can be achieved by knowledge graphs.
About the Authors
White Widget AI and Data Science Team excels in leveraging technologies such as machine learning, natural language processing, and generative AI, developing innovative solutions for the publishing, media, and entertainment industries—from crafting AI-driven games to enhancing public discourse and strategic decision-making through robust data analytics.
Primary Author
Jermaine P. a data engineer who focuses on emerging developments in AI and machine learning. A researcher and university educator, he's co-authored multiple papers on the subject, with special attention to NLP, semantic networks, and enhancing AI models using various techniques.
Contributors
Andrea L. brings over two decades of expertise in software engineering, product design, and cybersecurity to her role as Chief Technical Officer at White Widget.
Albert D. a data engineer who excels in AI-driven data analysis, system optimization, and meticulous adherence to best practices. He particularly excels in semantic engineering, transport and geospatial data analysis.