Article
Self-Hosting AI Stack Options in 2025: Edge-to-Cloud Strategies that Cut Costs
Last Updated on October 7, 2025
by White Widget AI and Data Science Team

Growtika | Unsplash
AI Hosting, Your Way
Key take-away:
Owning a self-hosted AI stack slashes costs and gives you control of your data, without compromising performance.
We delve into every hosting option from smartphone edge to cloud, and show how real organizations, even with partial adoption into self-hosted open-source AI solutions, got a positive net benefit.
Executive Snapshot: Why Move Now?
- Reduction on LLM cost per user vs. pay-per-token APIs
- Zero third-party data exposure is possible: meets GDPR, HIPAA, and PH Data Privacy Act Residency Rules
Open Source vs. Commercial LLMs: Performance Gap Is Getting Narrower
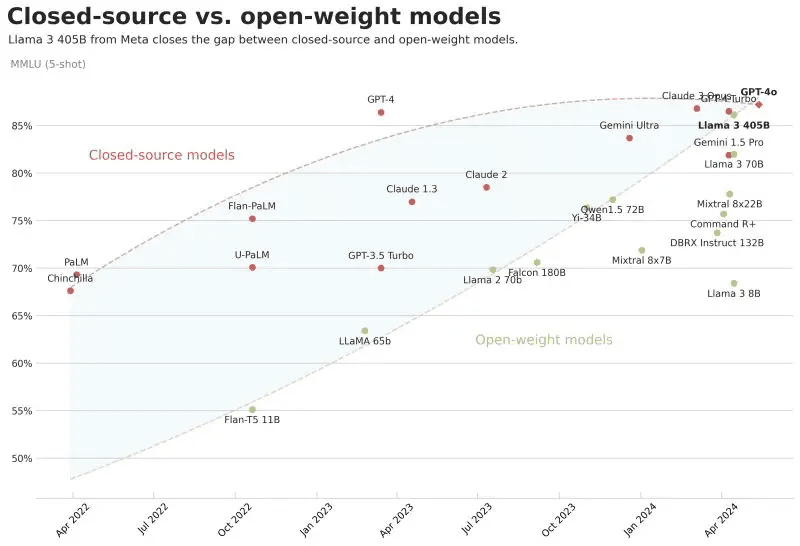
Fig 1: Performance Benchmark of Popular Open-Source Models compared with Closed-Source Models in Apr 2024
For a considerable period, commercial closed-source large language models (LLMs) offered by major tech companies, held a distinct performance advantage over their open-source counterparts.
However, recent trends indicate a significant narrowing down of the performance disparity, with open-source AI models rapidly catching up, and in some cases, even rivaling the performance of proprietary solutions.
With the help of open-source models, we can also design AI solutions that are not only high-performing, but also offer:
- Full observability and transparency — Review training data practices, model weights, and architectural choices.
- Deployment flexibility — Run on-premise or in private cloud environments, with custom memory and latency optimizations.
- Cost predictability — Avoid usage-based pricing models that can scale unpredictably with commercial APIs.
This shift opens up entirely new strategic possibilities: secure, self-hosted LLM deployments tailored to enterprise requirements without compromising on accuracy or speed.
Plugging Domain Gaps by Adding Knowledge Bases and Fine-Tuning
Open-source models still lack the proprietary facts and brand voice of the organization. To close the gap, two levers can be pulled:
- Connect a Knowledge Base: techniques like RAG can provide relevant context to the model so that it cites fresh, verifiable context as reference.
- Task-Specific Fine-Tuning: Imprinting your tone, policy rules, or structured output formats can be possible with fine-tuning.
The primary advantage of adding knowledge bases is its ability to keep the AI model’s knowledge up to date without the need for re-training or continuous fine-tuning. When new information becomes available, it can simply be added to the knowledge base, and the system will be able to incorporate it into future responses as further contexts.
Connect data sources for knowledge volatility; invoke fine-tuning when policy adherence or style precision matters.
Hosting Solutions
We will now explore different hosting solutions. When considering how to deploy AI solutions outside of public, black-box APIs, the solutions can be broadly categorized by the degree of infrastructure control and management burden undertaken by the users or organization.
This spectrum ranges from fully managed services that abstract away all infrastructure to bare-metal deployments where the engineering team manages everything.
Tier-by-Tier Executive Rundown
- Fully Managed APIs: These services provide access to latest models through an API, handling all infrastructure, scaling, maintenance and security. Privacy and security primarily rely on the provider’s security and compliance certifications. Data stays within the provider’s environment.
- Fastest pilot and teams focus solely on integrating the solution into their applications; but Operational expenses scale unpredictably. Good for early-stage prototyping and where speed-to-market is critical.
- Managed AI Platforms (Data and Workflow Focus): These platforms offer managed environment for machine learning lifecycle, from data preparation to model deployment and monitoring.
- Great bridge strategy while the skills of your team mature. The team owns the model checkpoints, rents the runtime for inference. This balances the control on user data and convenience on engineering teams.
- VPS / Dedicated GPU Hosting: Full control in your cloud tenancy; predictable spend; requires DevOps.
In this option, the engineering teams rent virtual machines or dedicated servers from a cloud provider, often with GPU support. This setup also empowers the engineering team to control the operating system and the software stack to be used. Hardware is still managed by the provider.
- On-Premises Hosting: In this option, the models are run directly on a dedicated workstation. This setup leverages the available hardware, often GPUs, for local inference of the model.
- Lowest long-run costs and maximum sovereignty; but requires significant Capital Expenses and facility readiness.
- On-Device / Edge AI: These are AI solutions that run directly on end-user devices such as smartphones, laptops or embedded systems. Ideal for frontline, offline or ultra-private workflows.
Self-Hosted Solutions: Stories with Positive-Net Benefits
Empowering Every Public Officer with AI tools: Singapore Government introduces PAIR, an AI Assistant for Public Service
Fig. 2: Singapore General Hospital harnessed the power of Pair to create Proph Abby, an AI assistant that checks compliance on surgical prophylaxis guidelines for complex surgical operations
- 12 agencies onboarded with 9 months
- 95% compliance with surgical-antibiotic guidelines at Singapore General Hospital
- More recently based on their timeline (PAIR), they shifted to Claude 3.5 Sonnet to gain performance boost
Self-Hosting AI in Dedicated Workstation: How White Widget setup Local LLMs with Ollama, Open Web UI and Tailscale for Internal Tooling
Here at White Widget, we saw the need to evaluate open-source AI solutions to our team without the immediate cloud overhead.
For example, we want to explore features like new embedding models, fine-tuning or even testing the open-source models out of the box. We also see the need for a setup that is collaborative, secure, and can be accessed internally by our team. The tech stack we used is available online, with Tailscale offering generous free tier which we used for setting up the private network.
Tailscale allows managing of remote access using Access Control Lists (ACLs). For example, we can make the dedicated workstation like WW Office Machine run and make ports visible.
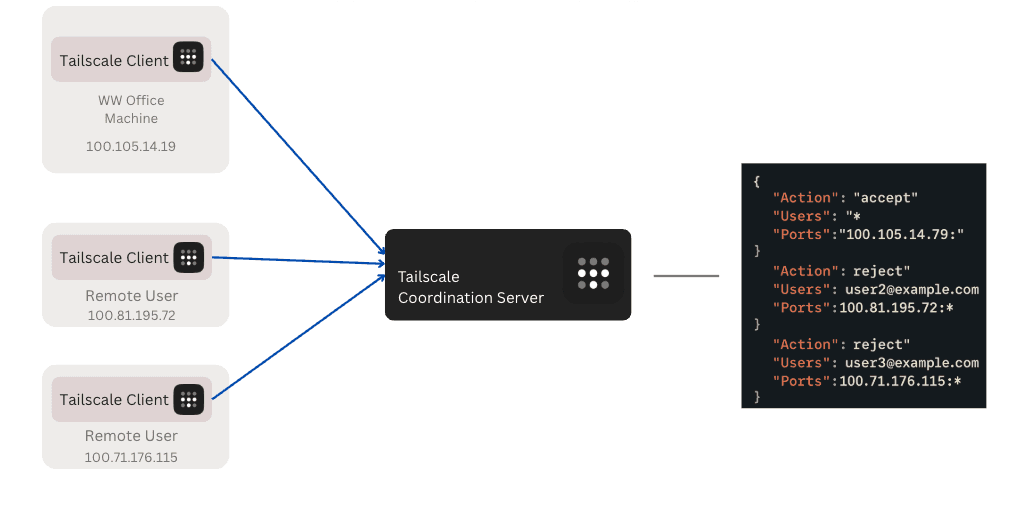
Fig. 3: Sample private network configuration with Tailscale ACL, only WW Office Machine is accessible in the private network without compromising the security of remote users in the private network
We will not dive deep into the Tailscale features, but with the help of Tailscale funnel and Tailscale serve, we can make services like Ollama API endpoints available online to engineering teams
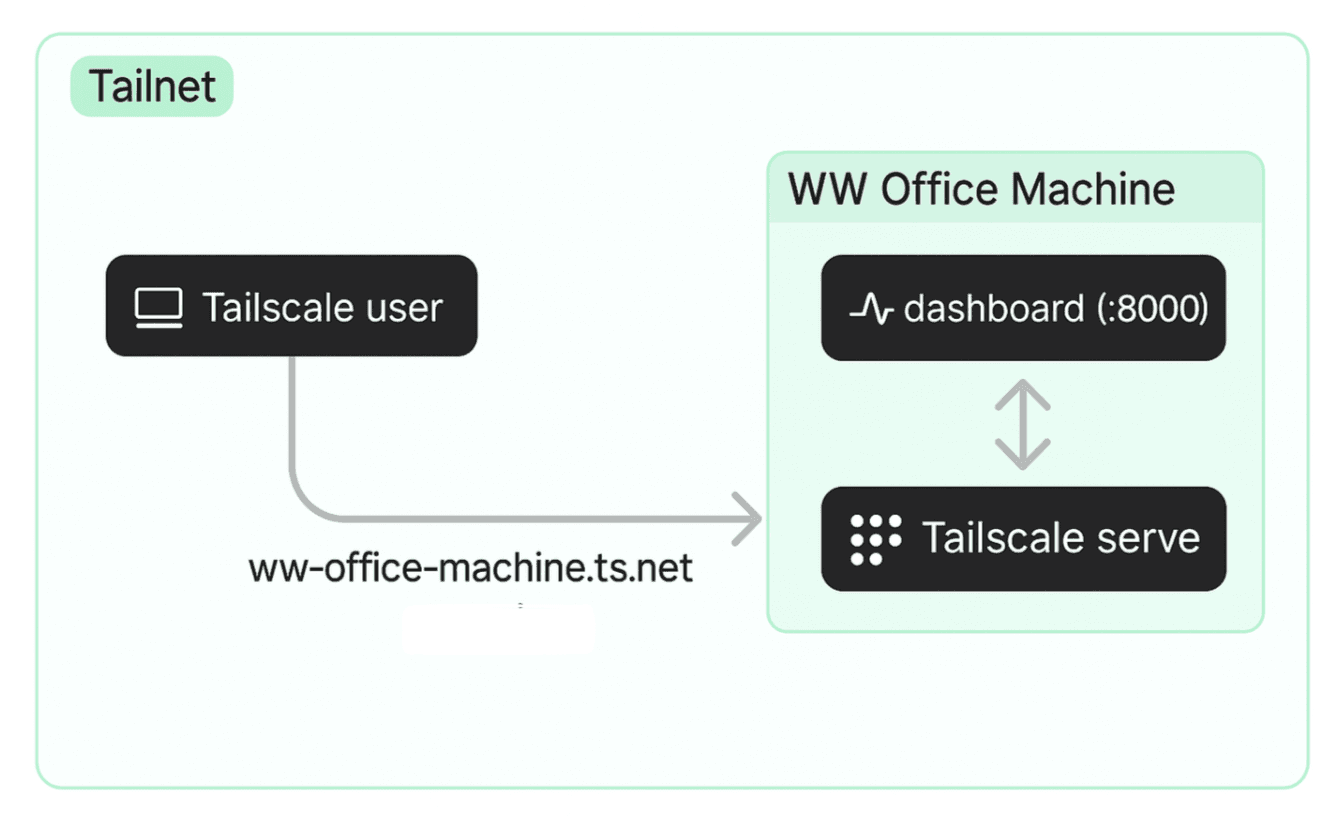
Fig. 4: Using tailscale serve, you can make web services available online to remote users or within the tailscale network
We used the setup to explore features like AI-assisted generation of documentation for our codebases, which our team is actively evaluating.
Having a dedicated workstation for hosting local LLMs can be cost-effective in developing internal tooling, which may help increase developer productivity and widen our capabilities by trying new technologies without the cloud overhead. While not good for production, it is a good sandbox for developing in-house tooling and experimenting with OSS features.
On-Device AI: Solutions Accessible Within your Smartphone
Last May 2025, Google has released a demo application called Gallery that allows users to run LLMs on mobile devices. You can access the GitHub repository to grab their latest APK installation. Currently, the demo application is only available to Android users, with potentially an iOS version under development.
Running models on-device means the user has to download the model weights first to the device, for example in smartphones, before using it. This setup offers numerous advantages, including faster latency with no network involved, guaranteed privacy because the data is not sent off device, and the setup also allows offline use without requiring cellular network or data consumption.
What’s impressive with the OOB models available in the app is that it can process and answer questions about images accurately. We ran the model on low-end, consumer phones.
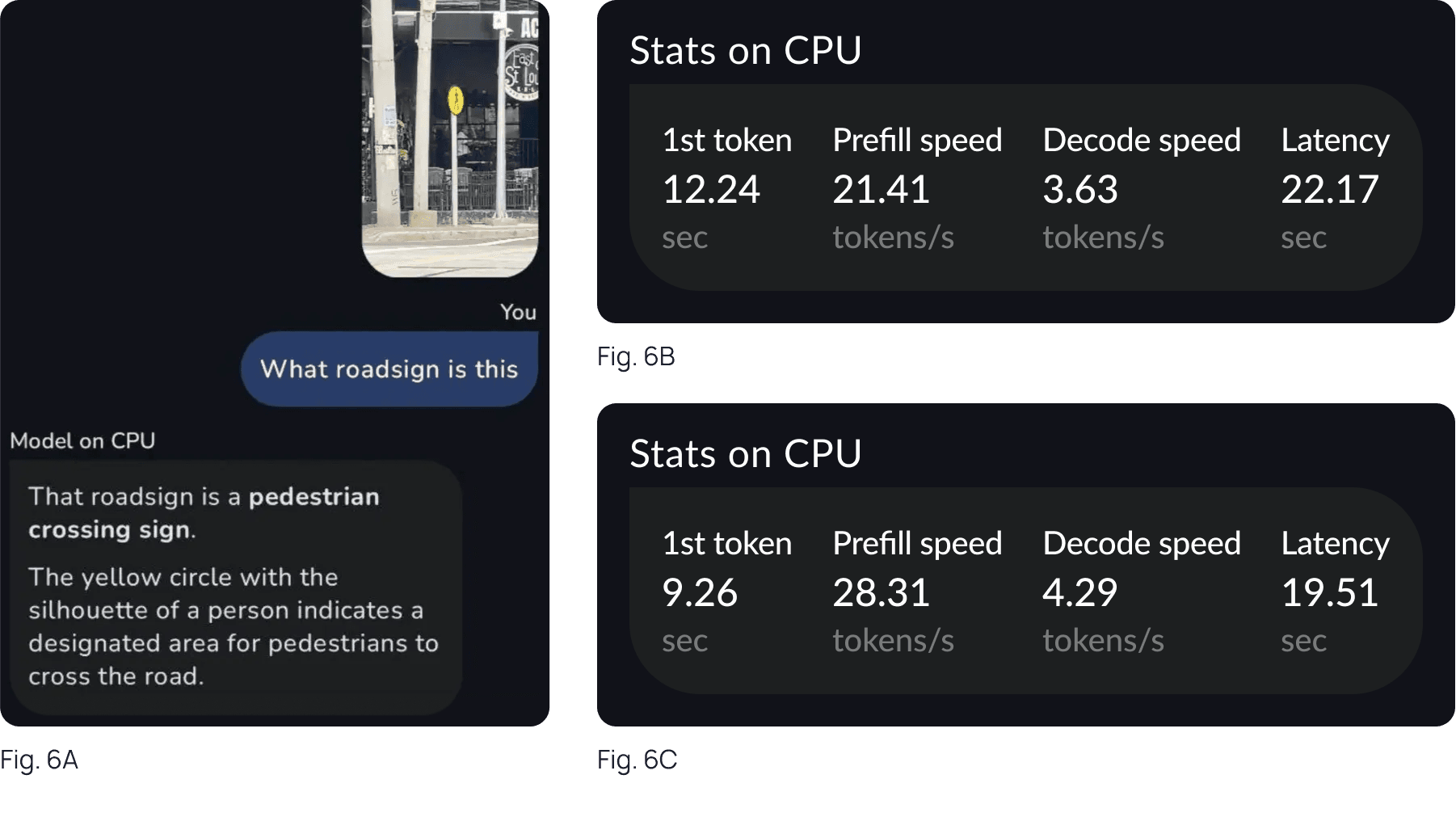
Fig. 6: We tried running this in our mobile devices and ask different questions about a given image we send. 6A shows a sample interaction with it. We also compared the statistics when running the model on CPU, shown in 6B, vs. when running the model on GPU, shown in 6C
Expanded Section: What those Metrics Mean
The Gallery provides useful metrics for assessing the model’s performance that is running on a smartphone.
First-token latency: measures the model startup, allocation of cache and reading the prompt to produce the first token.
Pre-fill speed: measures how fast the model reads the prompt.
Decode speed: measures how the model generates the answer with cache reuse.
End-to-end latency: the wall-clock time measured to generate the whole answer.
The performance out of the box looks impressive already given it runs on mobile devices.
Conclusion & Next Steps
Self-hosting now covers a wide spectrum from fully managed platforms that hide the plumbing to bare-metal clusters that give you total control. Now that open-source models are rapidly closing the performance gap with commercial offerings, and because techniques like adding knowledge bases and fine-tuning tools make customization possible, building your own AI stack is more feasible than ever.
The real-world wins back this up. Projects like Singapore’s Pair assistant shows how running models can deliver stronger privacy, tight security and lower long-term costs while letting the teams tailor the model to local regulations. Looking ahead, even on-device LLMs are pushing the same benefit to the edge, promising millisecond latency and zero-cloud data exposure for end-users.
Need Help in your AI Solutions?
Let our team help you cut costs on inference bills and cloud spend by exploring self-hosted and hybrid solutions.
References
- Pair Case Study “Proph Abby: Singapore General Hospital Leverages Pair to Revolutionise Surgical Antibiotic Prophylaxis”. blog link: https://pair.gov.sg/pages/case-studies/sgh-pair
- Pair Timeline Report “Updates”. link: https://reports.open.gov.sg/pair/updates
- Google AI Edge’s Gallery on GitHub: https://github.com/google-ai-edge/gallery
About the Authors
White Widget AI and Data Science Team excels in leveraging technologies such as machine learning, natural language processing, and generative AI, developing innovative solutions for the publishing, media, and entertainment industries—from crafting AI-driven games to enhancing public discourse and strategic decision-making through robust data analytics.
Primary Author
Jermaine P. a data engineer who focuses on emerging developments in AI and machine learning. A researcher and university educator, he's co-authored multiple papers on the subject, with special attention to NLP, semantic networks, and enhancing AI models using various techniques.