Article
Scraped by AI? The Signs You’re Being Harvested—and What to Do
Last Updated on October 7, 2025
by White Widget Team

White Widget Team
Protect your site from AI scrapers
Understanding Why AI Scrapes, What It Risks, and How to Respond — Strategically
Key take‑away:
Sustainable defense begins with understanding
why
automated AI scrapers bombard sites, what they can do with what they take, and which layered counter‑measures best fit your risk profile, budget, and values. WAF mitigation is one option; it is not the only tool in your arsenal.
Table
Why is AI Scraping the Web in 2025?
| Driver | What It Means for Site Owners |
|---|---|
| Data‑hungry model training | Frontier‑scale models still demand trillions of fresh tokens. Open‑source and closed labs race to widen their corpora faster than licensing can keep up. |
| Shadow‑copy competitors | Smaller players purchase or rent scraping APIs to clone niche knowledge bases, price catalogues, or feature descriptions. |
| Search‑engine disruption | Generative answers divert traffic away from origin sites, raising the incentive to ingest entire verticals for RAG pipelines. |
| Weak legal deterrents | Copyright doctrines around text‑and‑data mining remain unsettled in many jurisdictions, lowering the perceived cost of infringement. |
Scraping is no longer a random botnet pastime. It is now backed by venture money, GPU budgets, and service providers who sell scraping-as‑a‑service. Blocking requires more than rate‑limiting; it requires a multifaceted governance strategy.
Case Study — 131 k Requests, 104 Unique IPs, Zero Humans
On 12 May 2025 we noticed an unusual pattern in our alerts and logs for one of our customer websites:
- Low cache hit rate (15%): These bots were bypassing cached assets to pull raw content
- Anomaly in user requests: Low amount of unique visitors for a huge amount of traffic.
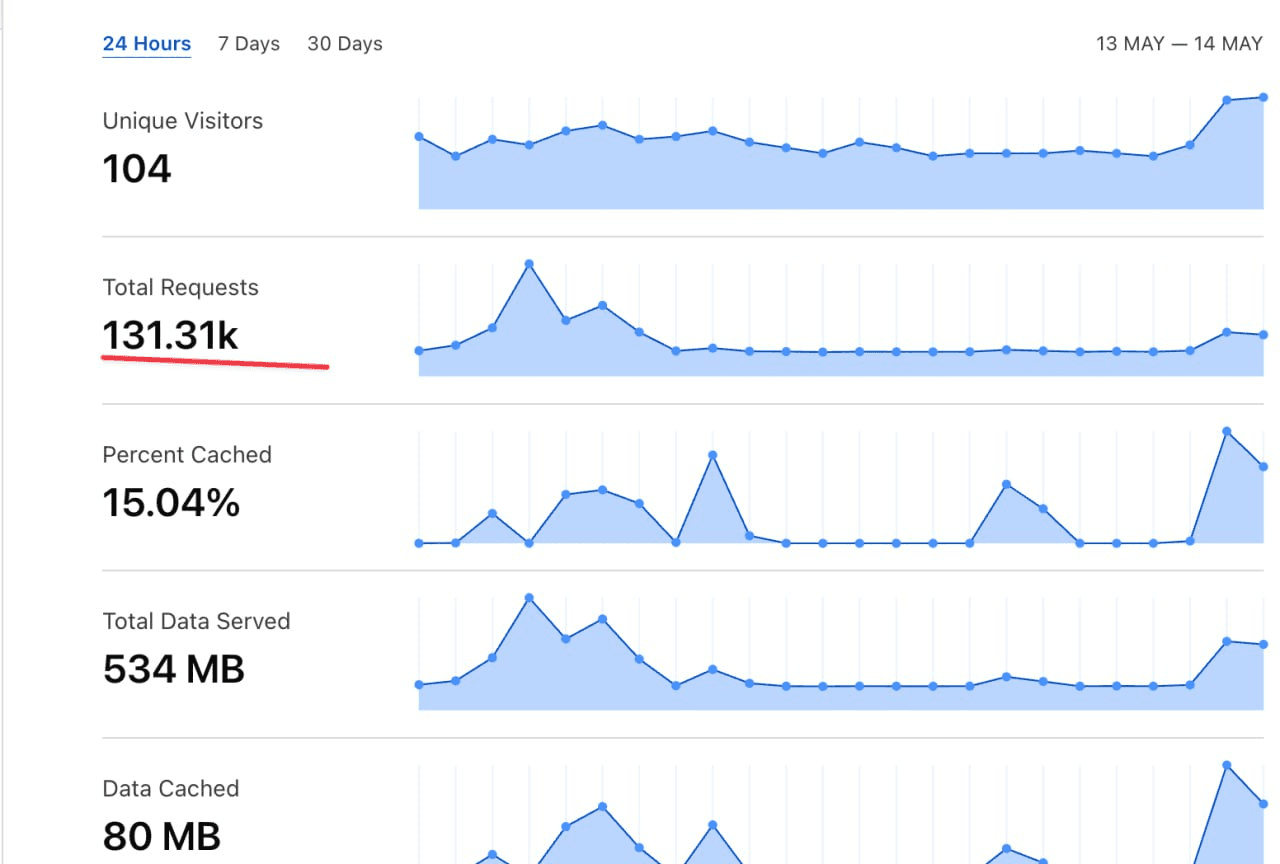
Our dashboard last May 12 has shown that the total requests had blown up to 131,000 requests, coming from just 104 unique visitors, with a low cache hit rate of 15%.
Why we believe it was an AI scraper, not a classical DDoS:
- Uniform traversal order — crawled sequential slugs sorted by publish date.
- No login attempts — content, not credentials, was the target.
- Traffic plateaued after 30 min — once the corpus was copied, the actor disappeared.
We could tell this was a targeted content scrape, likely for use in AI model training or competitive aggregation. If the site’s content later appears inside an LLM prompt with no attribution, our client’s brand voice dilutes, and their SEO moat narrows, not to mention the data mining implications.
We’re software developers, but our mission doesn’t end with deliverables. We worry about our clients, many of whom make a living creating original content.
And we’re not alone - across the web, many firms just like ours have been called in to rescue all types of sites that have gone under from aggressive AI scraping.
Not Just Us: AI-Fueled Attacks Are Becoming the Norm
This incident is just a small reflection of a global shift.
According to Cloudflare’s Q1 2025 DDoS Threat Report, the Internet is observing increasing levels of automated abuse, much of which is powered by AI-enhanced botnets. Here are the highlights:
- 20.5 million DDoS attacks mitigated in Q1 alone—a 358% year-over-year increase.
- Over 700 hyper-volumetric attacks, including:
- A 6.5 Tbps bandwidth flood
- A 4.8 billion packets-per-second attack
- New attack patterns that are randomized, bursty traffic that blends in with legitimate traffic
- Providers are selling AI-driven attack tools known as Botnet-as-a-Service
- High risk target industries like gaming and telecom, with a notable rise in incidents over Asia, Turkey, and Germany.
An in-depth discussion of the report is in Episode 92 of This Week in NET by Cloudflare Engineering:
While our incident wasn’t a DDoS, the scraping behavior we saw mirrored many of the same tactics. The automation no longer feels scrappy and brute-forced—it is optimized, trained, and harder to detect. These increasingly sophisticated attacks coincide with the dramatic advancements in AI.
This highlights a broader pattern: Automation and AI are transforming even the threat landscape.
What Can Happen Because of Unchecked Scraping?
- Competitive leap‑frogging — your hard‑won domain expertise becomes an answer commodity.
- Search cannibalization — AI‑generated summaries displace your SERP clicks.
- Compliance spill‑over — if your site hosts regulated data (e.g., health, financial data, unlicensed redistribution) can trigger liability in still‑evolving AI laws.
- Centralization pressure — every time a site relies on a single vendor to mitigate these issues, a little more of the open web moves behind a smaller set of (usually free-now-but-pay-later) chokepoints, ruining our collective freedom of expression and movement.
How Everyone is Responding
Now that AI vendors are routinely trawling web content to feed ever-growing large language models, a full spectrum of responses is taking shape.
Publishers, independent creators, and readers are pushing back to stop their words, images, and raw data from being used as training fuel for AI.
On the standards side, the Internet Engineering Task Force (IETF) has stepped in to calm the chaos. At last September’s workshop, the task force’s message was clear: we need a single, trustworthy signal that tells crawlers to train on this document or hands off on this document. We hope to move away from messy patchworks of robots.txt.
AI Preferences Working Group (AIPREF), a newly chartered IETF working group is formed with three deliverables:
- A shared vocabulary that allows authors and publishers to declare how (or whether) their content may be used for training and related tasks.
- A standard attachment method, whether embedded in the content itself or exposed via robots.txt-like manifests, and a reconciliation rule when multiple declarations collide.
- A compliance handshake that models can implement, so respecting preferences becomes table stakes, and not an afterthought.
While much of the work for standardization is ongoing, we can develop strategies now to fight back against scraping incidents.
Our Framework for Response
1. Set Visibility & Baseline
- Enable access logs at origin before touching any bot / WAF rules; We set up the pipeline and dashboard to ensure everyone sees the same numbers.
- Next, we overlay business metrics (bounce, conversion) on the dashboard to quantify impact, not just request counts.
2. Signal Our Policy & Ground Rules
- We maintain the evolving blacklist of AI agents in robots.txt. As new AI models appear, the list has to stay current, so we automate this for our customers.
- We can template structured data copyright notices (IFLA, CC licenses) for downstream legal claims.
3. Add Technical Friction (Pick‑and‑Mix that suits your stack)
- Edge bot‑management — Cloudflare, Fastly Bot Shield, Akamai Bot Manager, PerimeterX, or an open‑source Nginx/ModSecurity + CrowdSec stack. We prototype the rules and walk through your team through the changes.
- Behavioural WAF rules — Together we setup initially an appropriate threshold in challenging long‑tail IPs that hit > X posts/min with zero images/CSS.
- Honeypot schema traps — We can place hidden canonical links that leak only to scrapers.
- Token gating & signed URLs — Add short‑lived links for premium content.
4. Use the Legal & Commercial Levers
- We can team up as you draft the Terms‑of‑service clauses that prohibit automated extraction, and we surface the link headers.
- Registration with synthetic data registries.
- Consider licensing deals (like the New York Times’ + Amazon’s licensing deal) if your business model permits.
5. Keep Multi-Vendor Resilience
- Avoid single‑point dependency: run monitoring on origin + Content Delivery Network (CDN) + Real User Monitoring (RUM) so we can migrate if a vendor policy shift (or outage) harms you.
Table
Evaluating Bot‑Mitigation Vendors
| Question to Ask | Why It Matters |
|---|---|
| What PII is logged & for how long? | GDPR/PDPA exposure and partner risk. |
| Can I self‑host my WAF rules? | Prevents lock‑in, lets security team own playbooks. |
| How are false positives surfaced? | Editorial and content creation sites cannot afford to punish real readers. |
| What is the company’s stance on data‑for‑training deals? | Confirms alignment with your own policy. |
One of the most common bot mitigation vendors, Cloudflare, can be used as a solution. They offer features like Bot Fight Mode to lure bots into wasting their time following broken paths, and a feature to block AI bots and crawlers. It scores high on ease‑of‑use and integrated DDoS protection, but critics raise two recurring concerns:
- Traffic metadata centralization — one firm proxies ~20 % of global web traffic.
- Opaque zero‑day sharing — their WAF signatures are proprietary, making transparent outside review difficult.
A mature security posture acknowledges these trade‑offs and, where necessary, mitigates them.
What You Should Do Today
To get started, you can start with this checklist to audit your protection against bot attacks.
Table
What You Should Do Today
| Action | Why it Matters |
|---|---|
| Use robots.txt to block AI bot crawlers | Only stops ethical/respecting AI crawlers |
| Write WAF Rules | Blocks stealthy or disguised bots |
| Use Honeypot Trap to Reveal Bad Actors | Traps aggressive scrapers |
| Monitor logs regularly | Spot any patterns and blacklist observed IPs that are bad actors |
| Apply your tooling at the edge (WAF, Bot mitigation protocols) | Provides solutions for mitigating AI scraping |
Looking Forward — The Open Web vs. Model Hunger
Creators deserve to have a say in how their work trains tomorrow’s models. When scraping runs wild and is left unchecked, it erodes the very incentives that keep the open web alive, spiraling into what Dr. Cory Doctorow coined as the “enshittification of the Internet“.
The upside? You don’t have to wait for a standards committee to finish negotiating AI-content rules and how content gets consumed by scrapers. Engineering solutions are already at hand for you to apply and protect your content. Your defenses can start today.
Need a Second Pair of Eyes?
Our security engineering group has helped media, healthcare, fintech and civic‑tech platforms build unbiased, multi‑layered guardrails against scraping without locking themselves to one vendor. We can:
- Map your scrape surface in a few days
- Prototype vendor‑neutral WAF mitigation rules
- Facilitate the tech consulting side to help your legal counsel’s licensing options
Let’s talk about a defense that respects your users’ privacy and your IP.
About the Authors
White Widget Team is known for delivering holistic, award-winning software solutions across diverse sectors such as transport, healthcare, and media, emphasizing a comprehensive approach to digital innovation, since the company was founded in 2012.
Primary Author
Jermaine P. a data engineer who focuses on emerging developments in AI and machine learning. A researcher and university educator, he's co-authored multiple papers on the subject, with special attention to NLP, semantic networks, and enhancing AI models using various techniques.